Thanks for reporting this issue. Do I understand correctly, that you only have issues with this version of the scipt and that e.g. the version at fizban99/pp-portfolio-classifier works fine?
If this is the case, then my code seems to have a bug. Compared to the original version of the script, I try to retrieve data for more securities. I will try to reproduce your issue. Maybe I misunderstood how the xml looks like in cases where securities have been deleted or it is something completely different. If you have any idea, any hint or maybe an xml file that causes the issue, it would help :-).
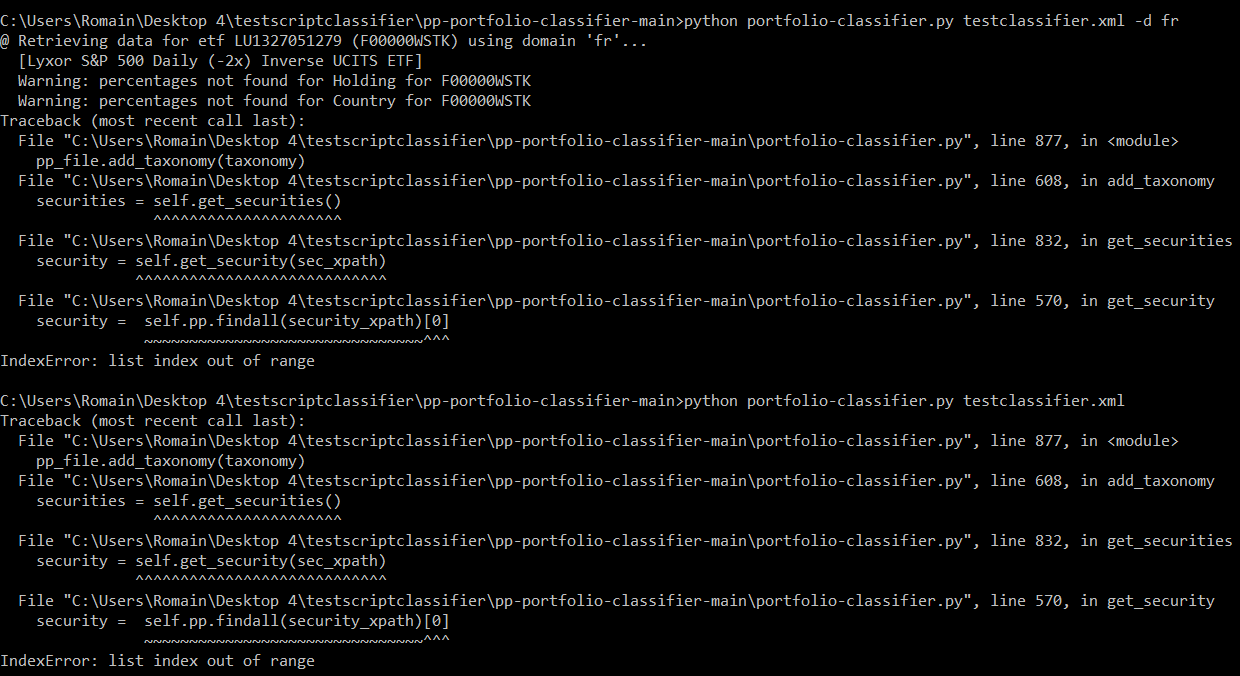
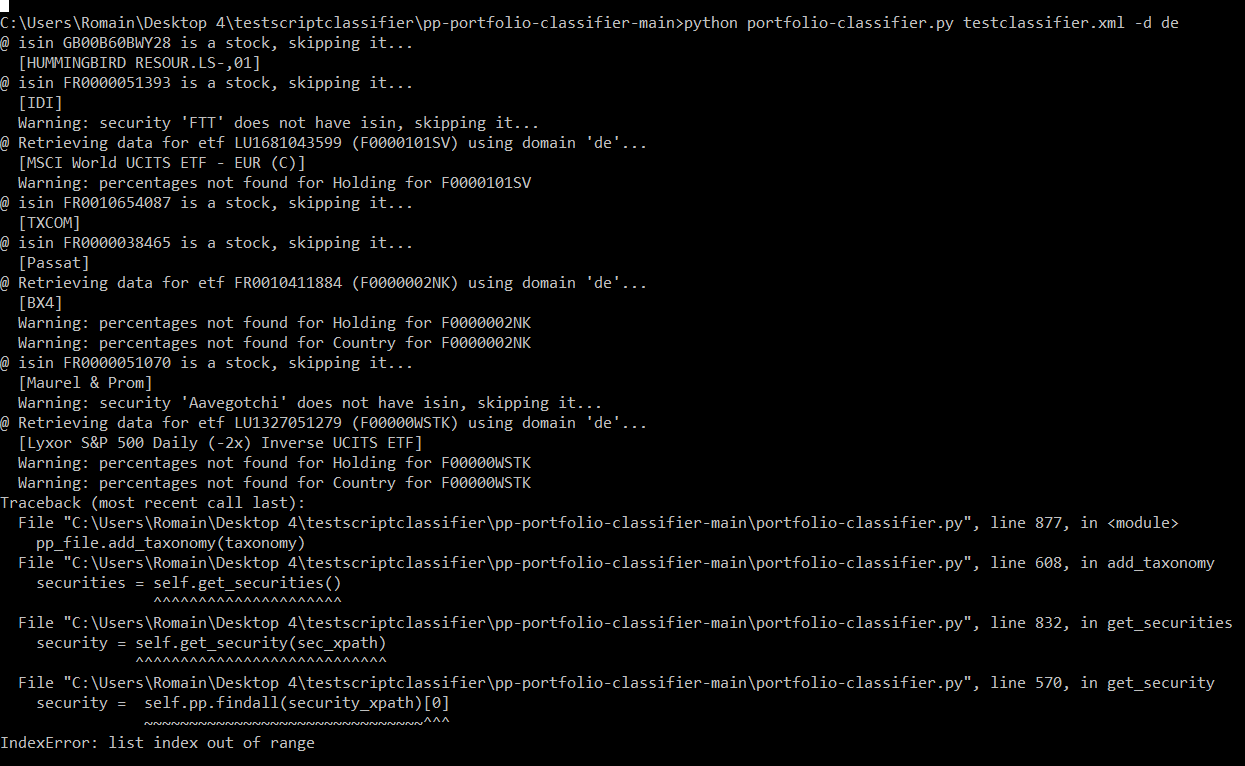
@spartok: Please try the new commit. I haven’t really understood why this issue is happening with your files, but I provided a fix for the error which is reported in your logs. Now the script should run through. But please check, if it really considers all your securities or if now it is missing some.
The data comes from the de domain. You could manually check the morningstar website if they provide data.
Otherwise you can change the domain and check again.
@spartok: Thanks for helping to debug my code. I am sure the issue is in my version of the script. I still haven’t found the full root cause of this issue. I think it is basically the same issue that you reported earlier. It is just that now I am circumventing it, but it also means that the problematic securities don’t get their data updated.
EDIT: I withdraw the following request. I am currently following an another trace (related to get_security_xpath_by_uuid). It might help me, if you could post a file with the result of:
grep -e "/security" testclassifier.xml
(A full xml creating the issue would of course help greatly).
(If anybody is interested: In the script I create a list of all possible xpathes for the securities in the xml. Then the script goes through this list and uses the xpath to pick a security to update its classifications. In the original version of the script, only valid dedicated xpathes which show up in transactions were used. For reasons which I have not yet understood, some of my xpathes create issues, i.e. they don’t lead to an actual security entry in the xml file. I have implemented a skip mechanism for those. But now it seems that I don’t catch all possible securities anymore. I could try a brute force mechanism by just making the list longer, but I would like to understand what is going on so that I can fix it in a clean way).
@spartok: I have now added an additional error message at a place where I suspect that it could be related to your issue. Could you please check, if you get it and how it looks like? This would fully match with what you experience. (Still I don’t know why it would occur).
print (f"Error: No xpath found for UUID '{uuid}'")
thanks a lot, all seems ok now, I can see all my etf listed in the taxonomies
FYI, I did not get any error message
Any chance to have the script also processing stocks ? I think it would be a great addition, and probably not too difficult to implement ? (as I see we can get stocks info from morning star the same way, getting a specific code etc )
maybe I’m missing the reason(s) on why it’s not possible and / or a bad idea ?
Yes, supporting stocks would be really great. Of course without top holdings, but rest of classifictions would be also great for single shares/stocks. I would guess (and hope) the api would behave very similar as for etf.
Good to hear that it works. Still I don’t understand what the original issue was. So if it occurs again, please let me know. (It might be that the issue occurs in a sporadic way. Then running the script multiple times will fill all data correctly even when in each run a different security is affected by the issue and not updated).
Please note that with the new version of the script, the classification of stocks is kept. So if you add them manually once, they will not be lost anymore. And usually, they are not very complex (one value per taxonomy) and also don’t change. Fetching them once is of course nice-to-have, but updateing them is maybe not such a big use case.
No, you don’t need to delete the taxonomies. You only need to delete (or re-name) them when you really want to re-build them from scratch as in the original version of the script.
Otherwise the workflow is as follows:
Use an existing xml file from PP (with or without taxonomies).
Run the script on the file (python portfolio-classifier.py myportfolio.xml myportfolio.xml)
Open the file in PP. ETFs/funds will have the classifications. Shares will not. (At least not, if they didn’t have them before).
Manually assign your shares to the matching classifications (e.g. TSMC as Stock, Large Value, Technology, Asia Developed, Taiwan) and if you want, assign some colours or whatever to them.
Your shares will now show up also in your graphs side-by-side with the ETFs/funds.
If you want, you can change colours or balancing weights or sequence or whatever of your classifications of ETFs/funds and also of shares.
After some time, run the script again (python portfolio-classifier.py myportfolio.xml myportfolio.xml).
Open it in PP. Your shares will still have the same classification (e.g. TSMC will still be Stock, Large Value, Technology, Asia Developed, Taiwan), your ETFs/funds will be updated with new percentages and new classifications (e.g. new holdings). Colours, balancing weights and sequence will be the same as before. Newly added classifications (e.g. a new holding) will have a colour assigned by the script.
Repeat whenever and as often as you want.
After a longer period of time, empty entries in Holding will accumulate (as companies join and drop from the Top10 of an ETF/fund). If you don’t want to have them, you can maually delete them in PP. (This can be done quite easily even if on first glance, it looks difficult, because PP only allows deletion of a single entry. But if you move entries under entries in a tree structure, you can delete the root of the tree an then all entries are gone).
but what about this part? my idea was to have the script handling it, like it’s already doing for ETF
Would that be possible?
doing it manually is quite cumbersome, as there are many information to check / retrieve, I have many stocks etc
And to me it looks like a similar process that this script should be able to do ?
but as mentioned before, maybe I’m missing the reason(s) on why it’s not possible and / or a bad idea ?
cheers
Yes, I guess this would be feasible, but I am not familiar with this part of the code and it wouldn’t be so easy for me. Actually, I share changes here which I do for my personal use. And fetching shares is not my top priority. If I find the time, I would rather like to focus on fetching holdings from other ISINs than the actual one, because sometimes MorningStar doesn’t provide the holdings for a specific ISIN (e.g. a synthetic ETF of the S&P 500), but of course other (physical) ETFs have the correct holdings (of e.g. the S&P 500). (Currently I solve this by giving my securities temporarily a wrong ISIN in PP which then fetches the holdings and in the next run I change the ISIN back and the holdings are not overwritten while the other taxonomies are updated to the correct values of the original ISIN again).
Well, I do it in a quite sophisticate way. I am sure, there are more simpIe ways.
I google potential candidates and put them into PP (in a separate file, just the instruments, no transactions). Then I run the new version of the script. (This is one of the reasons why I fetch data for all instruments, not just for those in portfolios). Besides the xml output, it now also creates the file pp_data_fetched.csv. If you open this as a spreadsheet (e.g. in Excel), it is quite easy to compare the different instruments (e.g. in a pivot table). Then I usually select the one which best represents the majority view.
I have now made a further enhancement: Script now supports a mechanism to retrieve classification from an alternative ISIN. It is used when MorningStar data for the native ISIN does not contain classification for a taxonomy. User needs to add #PPC:[ISIN2=XY0011223344] with the desired ISIN value to note field of the security in PP (besides other content).
@spartok: This is what I mentioned earlier. Maybe you could try it out to see how well it works. (I use #PPC:[ISIN2=IE00BFMXXD54] to fetch holdings for LU0496786574).