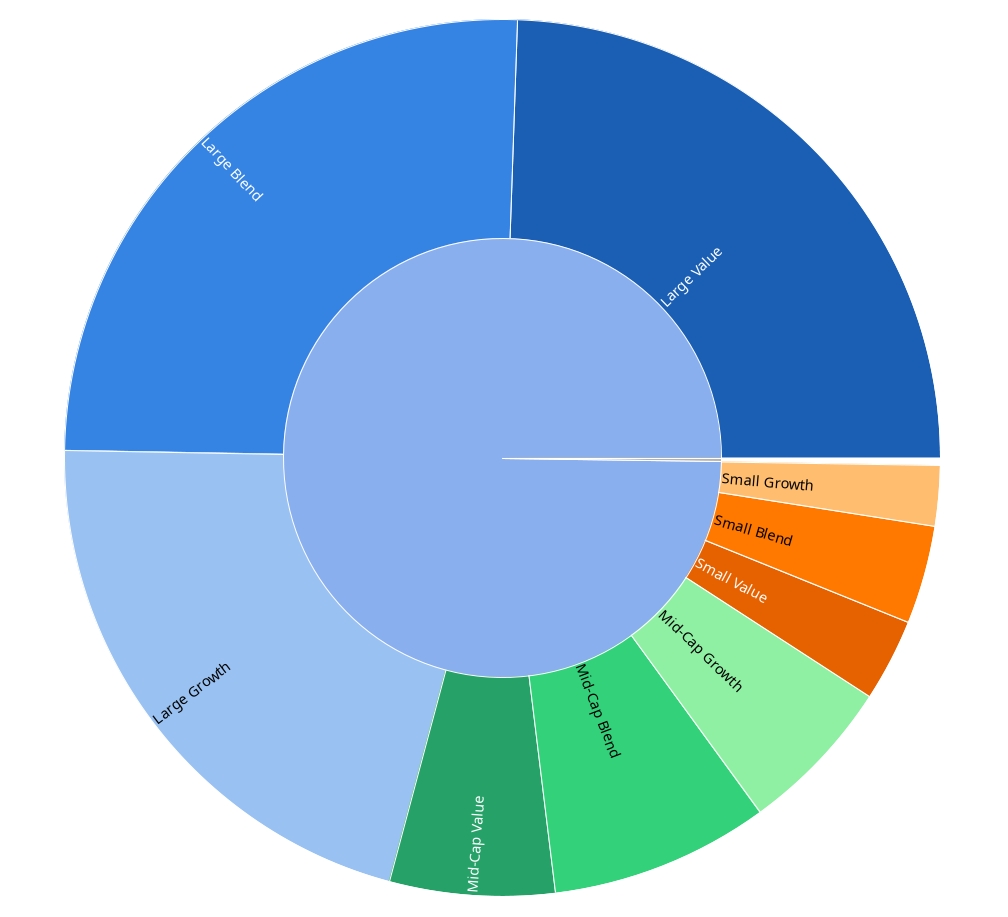
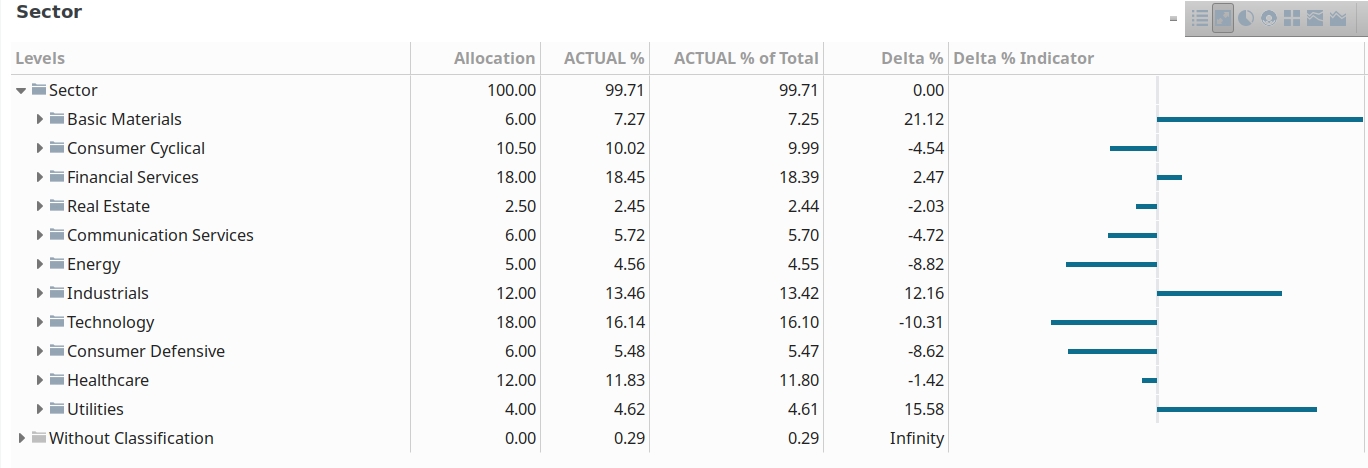
Yes, in most cases, it is only the top ten of the individual funds. My main use case is to make sure that my overall top ten do not get too much of a share. But of course, I miss the full picture if they occur also somewhere below the top ten of other individual funds.
Hi @Alfons1Qvor12 , now it’s works like a charm ![]() thank you for mantaining and updating this script keep it going
thank you for mantaining and updating this script keep it going
Hi @fizban,
Thank you very much for the great code. As you might have seen, I am currently working on some additional features for it.
In that context, I stumbled across your update from Mar 11, 2023 (commit fcee41e). I got the impression that the new lines 519 and 520:
if grouping_name in self.grouping:
continue
basically disable the x-ray retrieval. Was this by intention? When I remove them, I get x-ray retrieval back (for those cases when there are issues with snapshot). Would you recommend to keep this blocker? What are the reasons?
Thank you very much
Alfons1Qto12
Glad to see this project taking a new life. Regarding the if condition, I think it was related to certain classification groups not having information from Morningstar and then they were supposed to be retrieved from x-ray. If I find some time I will look into it.
Thanks. I have reactivated it in the meantime. In principle it still works well (except for holdings which I excluded). However, I am not sure, if there is really as use case for this backup mechansism as the api of the Morningstar site seems to provide sufficient information and because I have added a mechanism to fetch classification also from other ISINs.
(Currently I am thinking about fetching data for stocks from x-ray. I am confident that it is doable and on the other hand I am not sure if and how this could be done via the api. So the x-ray scraping will probably also be useful for that).
Great to hear that you think about stocks too. I guess I am not the only one with a lot of single shares beside etf, so much that I do not want to retrieve all data manually. Even if changes on stocks are seldom, changes will come. Especially for things like your show in your post here: Automatic import of classifications - #168 by Alfons1Qvor12 (Assets type Large blend, Small Growth, etc.)
So, also here an update at least every year makes sense, and having more as 100+ shares, will still make a lot of work.
Thanks for your great work and support. Also to @fizban for his work before.
+1000
would love stock support
Seems to be working fine for me. I see new classifications for my single-stock-PP-depot as following:
Stocks are assigned. Till now, I have not controlled if assignments were correct, but on fast overview it seems fine and consistent. There are some stock without classifications, but I have to check source manually if the stock really has no classifications or if it’s bug related. Most well known stocks have valid classifications.
Thanks a lot!
Hey, thanks for the script @Alfons1Qvor12 . However I seem to be having an issue: the script runs fine and generates pp_classified.xml, but I’m getting and error when trying to open it in PP:

And that part of the XML looks like this:
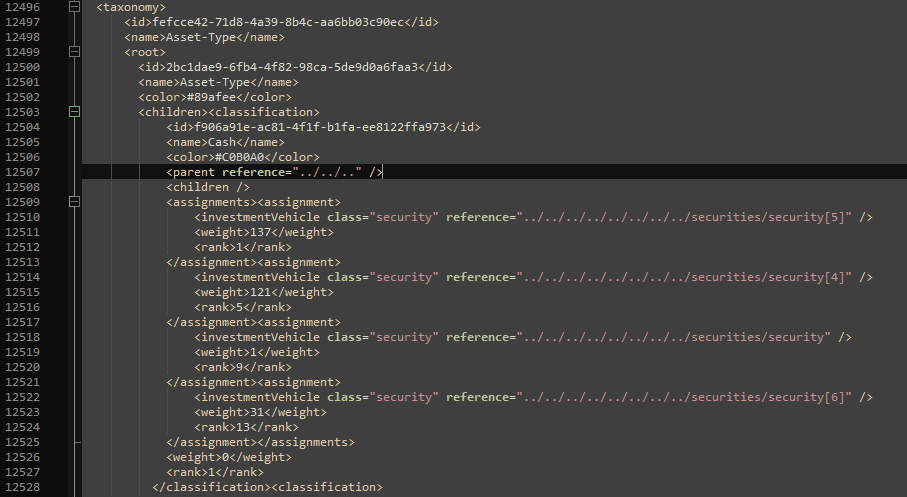
Any ideas on what could be happenning? Thanks!
Hmm. The xml looks exactly as it should. And the reference is perfectly ok. (It references to three levels up which are all available in the screenshot of your xml). I have no idea why it goes wrong.
I can create almost the same error, if I misspell the reference (xx instead of ..):

The only difference is that I see the path in my error message while it is missing in yours. I wonder if PP has somehow lost the path (litereally and figuratively ;-).
Maybe we can still check the overall structure of the xml, but I don’t expect a deviation from:
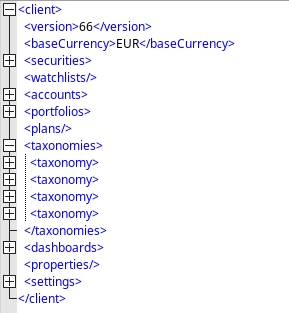
And maybe you can check, if the path /client/taxonomies/taxonomy/root/children/classification is valid in your xml (e.g. in XML Copy Editor via XML - Evaluate XPath).
Just to consider, PP introduce recently a new file type with absolute path references instead of the PP common relative once …
Thanks @rafa. This leads me to another aspect: @WiperWoper, are you using a recent version of PP?
AndreasB wrote about Version 0.70.3 / 5 August 2024:
Fix: Resolves - now hopefully all - issues where some XML files could not be opened due to the error message ‘invalid reference’.
Solution at the bottom.
@Alfons1Qvor12 answering your questions:
PP version:
Version: 0.71.2 (October 2024)
Platform: win32, x86_64
Overall XML structure seems fine to me:
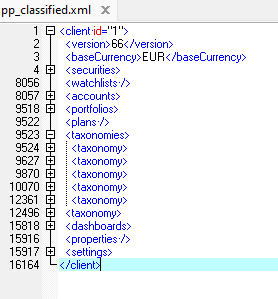
This is where I have a problem I think… I get this error: Cannot evaluate XPath: Error at line 0: Invalid expression. But I am getting that error even if just check for /client/ so… not sure what the problem is here.
EDIT: Figured out the issue. XPath evaluation also didn’t work with the original exported XML… and that’s because I exported “with id”. So I repeated the process by exporting an XML without ids, ran the script, loaded the classified portfolio… and it worked. Thank you again and sorry for the troubles!
Hi @spartok, any experience with the new functionality -stocks?
Hi mate,
Actually just before you released the update, I spent some time to manually categorize my stocks, checking each of them manually through morningstar website
I don’t have new stocks, but as soon as I have new lines in my portfolio, I’ll make sure to give it a go & let you know
cheers
Or give it a try and check for same results. ![]()
That’s what I thought as well ;-). And on top: All the information will be available in an Excel sheet (pp_data_fetched.csv) for further processing.
I tried but it doesn’t work. Can somebody tell me what i’m doing wrong?
Here the command and the messge i receive.
Thanks in advance
C:\Programmi\portfolioperformance\POrtfolioClassifier>python portfolio-classifier.py portfolioperformance.xml pp.xml -it -stocks -xr
Traceback (most recent call last):
File “C:\Programmi\portfolioperformance\POrtfolioClassifier\portfolio-classifier.py”, line 11, in
import requests
File “C:\Users\Pentaho\AppData\Local\Programs\Python\Python313\Lib\site-packages\requests_init_.py”, line 43, in
import urllib3
File “C:\Users\Pentaho\AppData\Local\Programs\Python\Python313\Lib\site-packages\urllib3_init_.py”, line 7, in
from .connectionpool import HTTPConnectionPool, HTTPSConnectionPool, connection_from_url
File “C:\Users\Pentaho\AppData\Local\Programs\Python\Python313\Lib\site-packages\urllib3\connectionpool.py”, line 11, in
from .exceptions import (
…<13 lines>…
)
File “C:\Users\Pentaho\AppData\Local\Programs\Python\Python313\Lib\site-packages\urllib3\exceptions.py”, line 2, in
from .packages.six.moves.http_client import IncompleteRead as httplib_IncompleteRead
ModuleNotFoundError: No module named ‘urllib3.packages.six.moves’