Danke!
Jein.
- Außerhalb von Zeichenklassen: ja (d.h.
1\.2matched nur “1.2”). - Innerhalb von Zeichenklassen: nein (d.h.
1[.]2matched auch nur “1.2”, genau wie1[\.]2). Siehe regex101.com:

(Vgl. auch https://stackoverflow.com/a/32272425 und die folgende Antwort)
Ähnliches gilt übrigens für [\w]{3}: \w ist schon eine Zeichenklasse (nämlich alle “Wortzeichen”), man braucht das nicht noch einmal in eine Zeichenklasse zu packen. Anders gesagt: \w{3} ist genau dasselbe wie [\w]{3}.
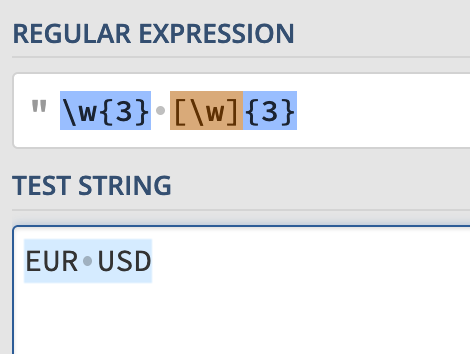
Die REs sind selbstverständlich nicht falsch, nur etwas ausführlicher als nötig. Darauf wollte ich hinweisen (denn REs sind ja ohnehin schon nicht lesefreundlich, deshalb mE lieber so kurz wie möglich schreiben).
Ja, ich weiß. RE waren praktisch meine Muttermilch.