Great!!! It worked perfectly. All the equity ETFs were identified, and the composition was determined according to the various clusters. In the pie charts, is it possible to display only the classified component? (I couldn’t manage to do it by playing with the filters).
Not sure, if I undestand your question. But if you click at the settings symbol in pie charts (and also in donut charts), you can untick the option “Include ‘Without Classification’ ”.
Hallo @Carsten ,
Du scheinst ein Wertpapier zweimal in PP erfasst zu haben - einmal mit 4.8%, einmal mit 5% zugeordnet.
Weil als erstes nach der ISIN gesucht wird, wird das selbe Wertpapier gefunden - zunächst auf 4.8 und dann auf 5.0 geändert. Und das wird als Änderung notiert. Und weil es die gleiche Zuordnung ist, aber auch nur einmal.
{
"identifiers": {
"name": "ACATIS AI Global Equities C",
"isin": "DE000A2DMV81",
"ticker": "0P0001B85G.F"
},
"categories": [
{
"path": [
"BASIC MATERIALS"
],
"weight": 4.8
},
[...]
{
"identifiers": {
"name": "Acatis AI Global Equities C",
"isin": "DE000A2DMV81"
},
"categories": [
{
"path": [
"BASIC MATERIALS"
],
"weight": 5.0
},
Die Frage ist wie ich damit am besten umgehe? Reicht eine Warnung? Solle ich alle Wertpapiere, die die gleiche ISIN haben anpassen?
PP ist leider (oder auch zum Glück) recht flexibel wenn es um die Wertpapiere geht…
Hi, I tested it on my portfolio. For the equity ETFs everything works perfectly, as well as for the individual stocks. However, it doesn’t work for the bond ETFs. Maybe I’m doing something wrong, or forgetting a command? My bond ETFs are for example IE00BH04GL39, LU1650491282
It seems that it doesn’t process information related to bonds and doesn’t create the following sections:
-
Bond Style (is new)
-
Bond Sector (is new)
Thanks in advance for your help, and congratulations on the great work you’ve done so far!
Here is result of -h:
usage: portfolio-classifier.py [-h] [-d DOMAIN] [-stocks]
[-top_holdings {0,10,25,50,100,1000,3200}]
[-bonds_in_funds] [-seg_bonds]
input_file [output_file]
reads a portfolio performance xml file and auto-classifies the securities in
it by asset-type, stock-style, sector, holdings, region and country weights
For each security, you need to have an ISIN
positional arguments:
input_file path to unencrypted pp.xml file
output_file path to auto-classified output file
options:
-h, --help show this help message and exit
-d DOMAIN Morningstar domain from which to retrieve the
Morningstar authentication token (default: de)
-stocks currently disabled (used to activate retrieval of
stocks from Morningstar Instant X-Ray)
-top_holdings {0,10,25,50,100,1000,3200}
defines how many top holdings are retrieved for
etfs/funds (values above 100 are not recommended in
combination with use in PP, '0' keeps existing holding
data)
-bonds_in_funds also retrieves information on bonds in funds (for Bond
Style, Bond Sector, Country, Region, Holding) and
generally includes more fund types in classification
-seg_bonds enables segregation of bond-related categories in
Country and Region, creates e.g. new "France (Bonds)"
entry instead of or in addition to "France";
recommended to either use always or never for a
particular xml file (otherwise additional entries need
to be cleaned up manually when they are not
wanted/needed anymore)
So please use -bonds_in_funds command line option (or just -bonds)
(BTW: -stocks works fine. I forgot to update the help text. Will do soon).
Hi @AndreasB,
It would be nice to have also the colour of the taxonomy exported/imported.
So instead of:
{
"name": "Asset Type",
"categories": [
{
"name": "Cash",
"color": "#8ff0a4"
},
{
"name": "Other",
"color": "#c0bfbc"
},
{
"name": "Stocks",
"color": "#1a5fb4"
},
{
"name": "Bonds",
"color": "#62a0ea"
}
]
}
It would be:
{
"name": "Asset Type",
"color": "#8ff0a4",
"categories": [
{
"name": "Cash",
"color": "#8ff0a4"
},
{
"name": "Other",
"color": "#c0bfbc"
},
{
"name": "Stocks",
"color": "#1a5fb4"
},
{
"name": "Bonds",
"color": "#62a0ea"
}
]
}
UPDATE: Actually it already works for import. But it is not part of export as far as I can see.
Hallo Thomas,
du hast Recht. Der Fehler tritt bei doppelten Wertpapieren mit gleicher ISIN auf, aber auch wenn die Sektorzuordnung über 100% liegt. Eine Warnung für doppelte ISINs oder über 100% Allokation bei der Konsistenzprüfung oder beim Export der JSON wäre hilfreich. Beim Import der JSON macht es Sinn alle Wertpapiere mit der gleichen ISIN einheitlich anzupassen. Es mag sicher Fälle geben die zu eine absichtlichen Doppelterfassung der gleichen ISIN führen, ich sehe aber keinen Grund warum man mit unterschiedlichen Sektorallokationen arbeiten will oder müsste.
With Version 0.79.0 I added more enhancements namely bulk import and export and the option to prune categories and assignments that do not exist in the JSON import file. The import should also print warning messages if multiple instruments are matched by one entry in JSON.
This is not done yet. One thing still on the list is how to learn about the not yet classified instruments. I am unsure if I want to include them in the export (and potentially duplicate them when doing a bulk export). Alternatively, I could create a separate export file. Finally, I want to add the option to call an external script for updating - that script gets the exported taxonomies, runs, and after that the import dialog is started. Stay tuned.
I have started to experiment with this and find it very interesting. Thank you for all the effort that has gone in.
I have a couple of questions.
1. When I look at the Taxonomy of some securities I find a lot of “without classification”… eg “Amundi (was Lyxor) Smart Overnight Return” with ISIN LU1230136894 (ticker csh2.l)… Do I have to manually add the taxonomy for this (eg moneymarket like)
2. The deposit accounts are also “without classification”… shouldn’t these be classified as cash … or is that for me to manually assign it?
3. If I end up with a mixture of automatic & manual assignment … how is it handled? Is there an option in portfolio-classifier to replace/keep/update manual assignment if it finds matching taxonomy online?
Ps (to get it working I had to upgrade my python and also add ISINs to my pp securities … as many of them only had tickers to allow the quotes to be retrieved from yahoo finance).
Again my thanks to pp & portfolio-classifier developers
Hi,
Thanks for using the script.
Ad 1: There are many types of funds and the script currently only supports some. LU1230136894 is of fund type “Money Market” which is not yet included and Morningstar actually provides not much information on that fund type except that Asset Allocation is 100% “Other”. So yes, please add manually whatever you think is suitable.
Ad 2: The script is built for retreiving non-obvious or more dynamic information. So yes, if you want to classify your deposit accounts, please set them manually. Please note that you are free to extend the taxonomies. The script will not overwrite unknown ones. So you could also define some other category than “Cash” for those.
Ad 3: The script will not overwrite taxonomies for which it was not able to retrieve anything. If you want to be on the safe side, add #PPC:SKIP to the Note attribute of the security which you want to maintain manually.
One more remark: For some securities (especially synthetic ones), Morningstar does not provide the holdings. For such cases, you may add someting like #PPC:[ISIN2=IE00BFMXXD54]to the Note attribute of the security. If the script doesn’t find any information on holdings, it will use this alternative ISIN (from some other fund) to retrieve the holdings of that one. In multifaktortest.xml, there is such an example for LU0496786574 and the above mentioned IE00BFMXXD54 as ISIN2.
Thank you very much @AndreasB. I like the new bulk import a lot. For me, it is especially useful for defining colours and sequence of categories.
I put a json file to github for import of defined colours for all categories (and in a certain sequence when imported from scratch) for all taxonomies in new-api-branch of Alfons1Qto12 /pp-portfolio-classifier, in case anybody is interested.
See: pp-portfolio-classifier/docs/taxonomy-json-templates/AllTaxonomies.json at new-api-branch · Alfons1Qto12/pp-portfolio-classifier · GitHub
Hello and thank all contributors for their work on PP and also on the classifier script.
Which I tested, and had to implement one code correction.
In the portfolio-classifier.py file, the line 1276 comes as follow :
print (f"\n +{"-"*115}+")
The double quotes (sourounding the - sign) inside the f-string double quotes yield to an error.
To correct it, these double quotes must be modified in simple quotes :
print (f"\n +{'-'*115}+")
I tried to put this information on the github repo, but I couldn’t, so this forum post, hoping it helps !
Regards
Thanks @toto330 for the hint, I have updated the code accordingly.
Please note that this is a new piece of code in new-api-branch for a new feature that calculates the German Vorabpauschale per share for funds.
@All: If anybody would be willing to test this new feature, this would be very helpful.
portfolio-classifier.py -voapa 2024input_file calculates the German Vorabpauschale for the year 2024 and you could compare it with the actual values from January 2025.
portfolio-classifier.py -voapa 2025input_file calculates the German Vorabpauschale for the year 2025 based on current stock prices and already paid dividends. The final value at the end of the year will be different, but it already gives a first indication.
Note that there is also the following command line paramter:
-ki_voapa {0,8,9} It defines personal Kirchensteuersatz applied to German “Vorabpauschale” (default: 8(%)), see also -help.
Great tool! Thanks for sharing it! Shame on me I only discovered it now…
In the Portfolio Performance GUI it’s possible to have a hierarchical structure, e.g. region → country. How should I adapt the script so that it classifies it like this? There is already a nice mapping of each country to a region so the manual work is already done. However, I have no idea how the hierarchy should be implemented for PP (and I have very limited coding skills)
Hi @riddleculous,
Interesting idea. If I find some time for it, I will prototype it and let you know. I agree that it would be nice to see which share of a region a certain country has and if e.g. one or more countries dominate the region.
A few thoughts/comments:
- From Morningstar, we usually get separate values for regions and for countries. Not sure, if they can be merged consistently, but it would definitely be an option to keep Region as a stand-alone taxonomy and to structure taxonomy Country by region (and and it would be interesting to see, if this then matches the Morningstar numbers for region).
- The mapping table in the code for mapping country to region is currently only used for cases where I couldn’t find the data on region in the Morningstar data (e.g. for individual stocks or for bonds in funds).
- Creating the hierarchical structure from scratch should not be a big issue. Integrating it with the other options how to structure the data and maintaining multiple options (and their co-existence), is probably a bit a more challenging.
Hello @AndreasB,
I have a small issue with the import/export of taxonomies: In the xml, each category has a “weight” value. This is used in the rebalancing tab to hold the value of “Allocation” (and typically the sum of all allocations of all categories should be 100). Whenever a new category is imported as part of a taxonomy json file, the value of weight for this new category is set to 100 during import. This is pretty inconvenient, because it destroys the property of sum of all allocations equals 100 and has to be manually changed. Would it be possible to default this to 0 instead of 100?
(Of course, having the option to include weight in the json import would be even better. And getting it as part of the export would also be quite nice, though less relevant to me).
Thanks
A1Qv12
Hello @riddleculous,
new-api-branch now has command line option -country_by_region. Please check.
(Creates new or updates existing taxonomy “Country@Region” which groups countries by region in addition to taxonomy "Country”).
With Version 0.80.2 is the default changed to 0 (I did not have the time to enable the import/export of the weight. I am also not so sure if that is needed, because it is used for rebalancing and I guess rarely changes).
Thank you very much for the fast fix!
I agree that the weight value doesn’t change frequently enough to justify the import. However, my use case is a different one. As rank value is not supported, it is not possible to restore or change the sequence of categories via import. (Example: When users sort countries by size of investment, they cannot go back to their original sequence which was e.g. based on geography and for which the colouring was done in a nice way). My workaround for that is to delete the taxonomy as a whole and load it again from a json template. In such case, the weight values are all gone and I have to enter them manually again.
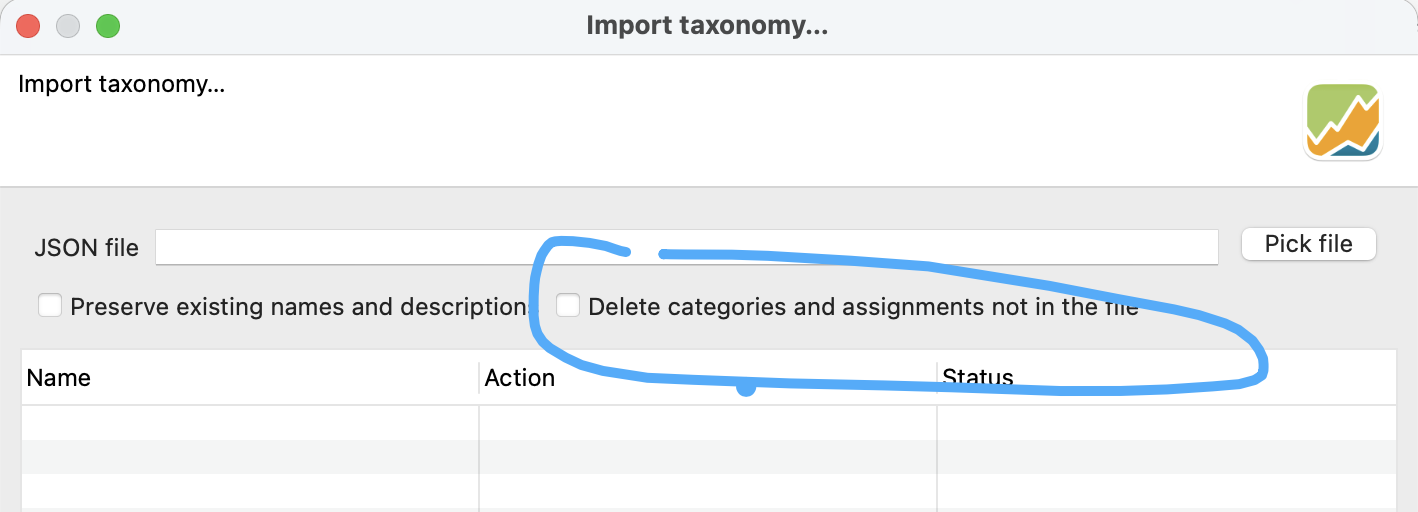
The “Delete categories and assignments not in the file” option will make sure the categories are in the order in which they are in the JSON file. (Maybe I have to think of a better label - it is also removing categories and assignments not in the JSON import file).
This should be the equivalent of “delete and re-create” except
- existing categories are updated, not recreated (hence the weight is kept)
- if you use the “classification key” to identify the category (instead of the path), then the user could also provide its own name (for example translate the category to “Deutschland” but the category key “DE” still identifies it)