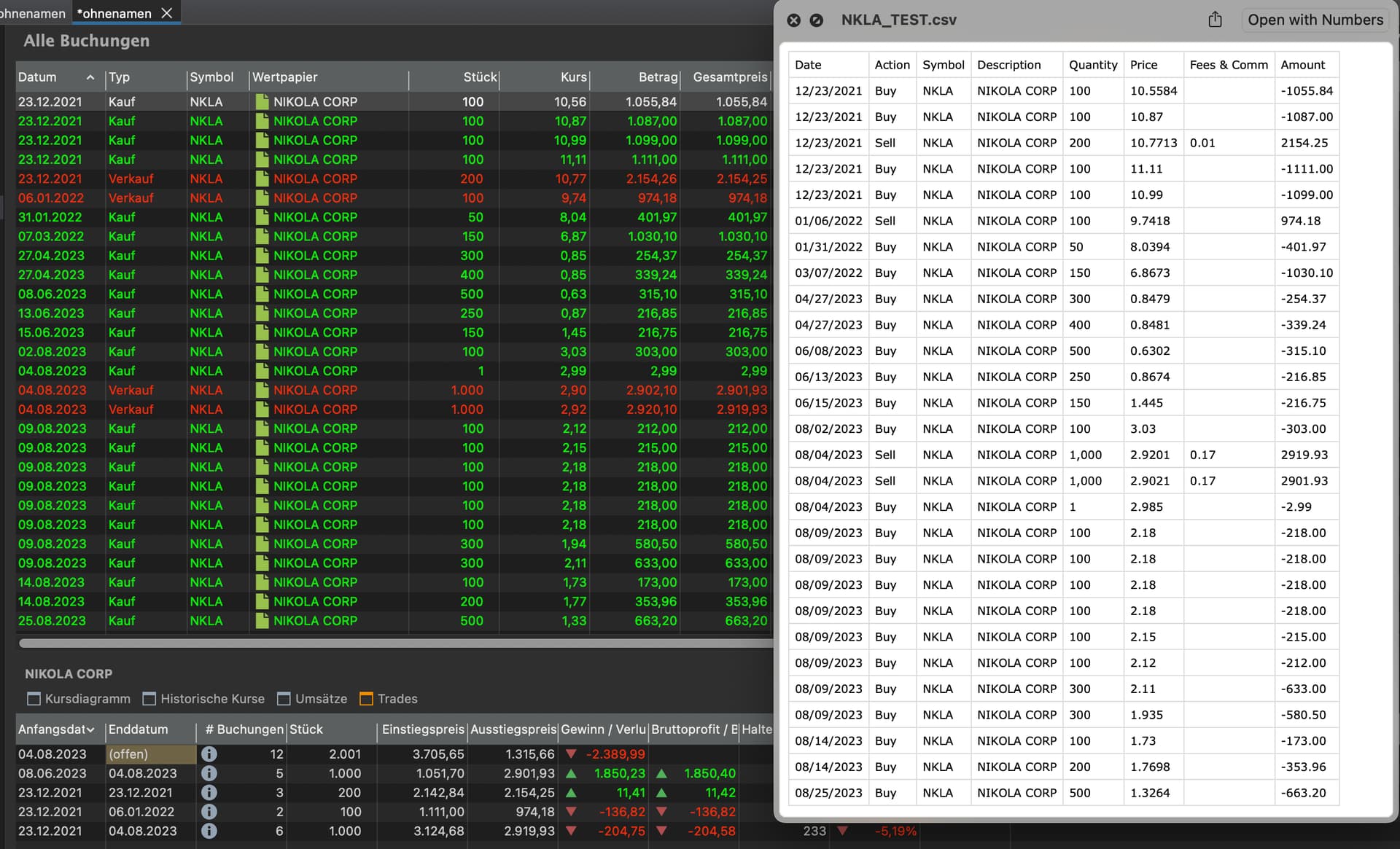
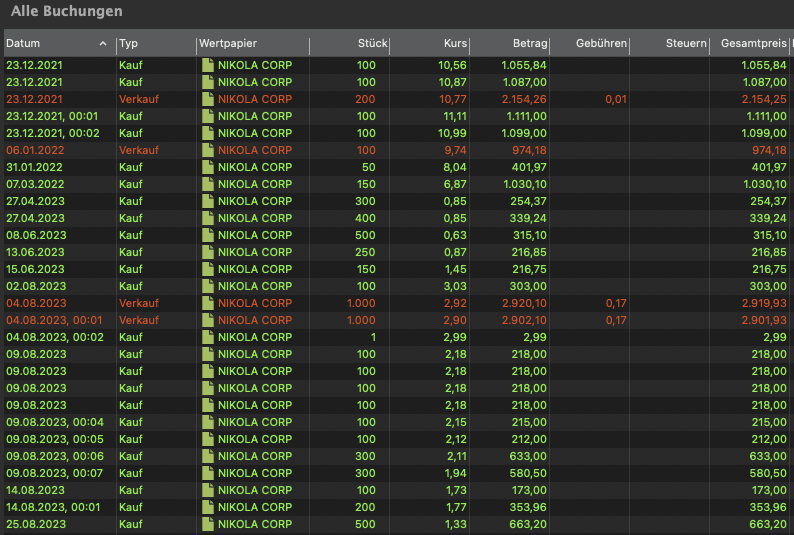
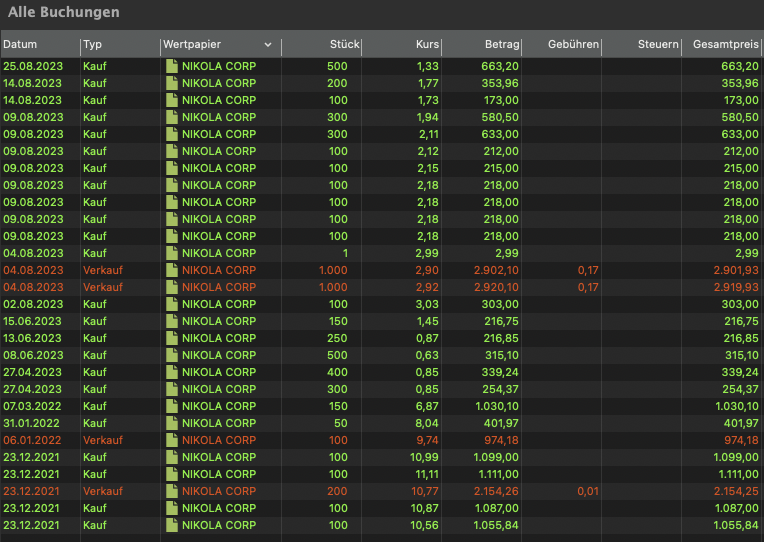
Sortierung nach Typ: PP sortiert Einträge ohne Uhrzeit mit gleichem Datum beim Import aus einer CSV-Datei nach Typ (z.B. “Kauf” vor “Verkauf”).
Reihenfolge innerhalb eines Typs: Die Sortierung innerhalb eines Typs, wie “Kauf” entspricht größtenteils der Reihenfolge in der CSV-Datei, jedoch nicht immer (siehe Screenshot).
Gewünschtes Verhalten:
Einhaltung der Reihenfolge: Um eine korrekte Berechnung der einzelnen Trades und der FIFO-Methode bei Einträgen mit fehlender Uhrzeit zu gewährleisten, wäre es wünschenswert wenn PP die Möglichkeit bieten würde, Transaktionen genau in der Reihenfolge zu importieren, wie sie in der CSV-Datei aufgeführt sind.
Optionale Einstellung: Falls dies generell problematisch ist, wäre eine zusätzliche Option im Importmenü wünschenswert, um die Reihenfolge bei Bedarf anzupassen.
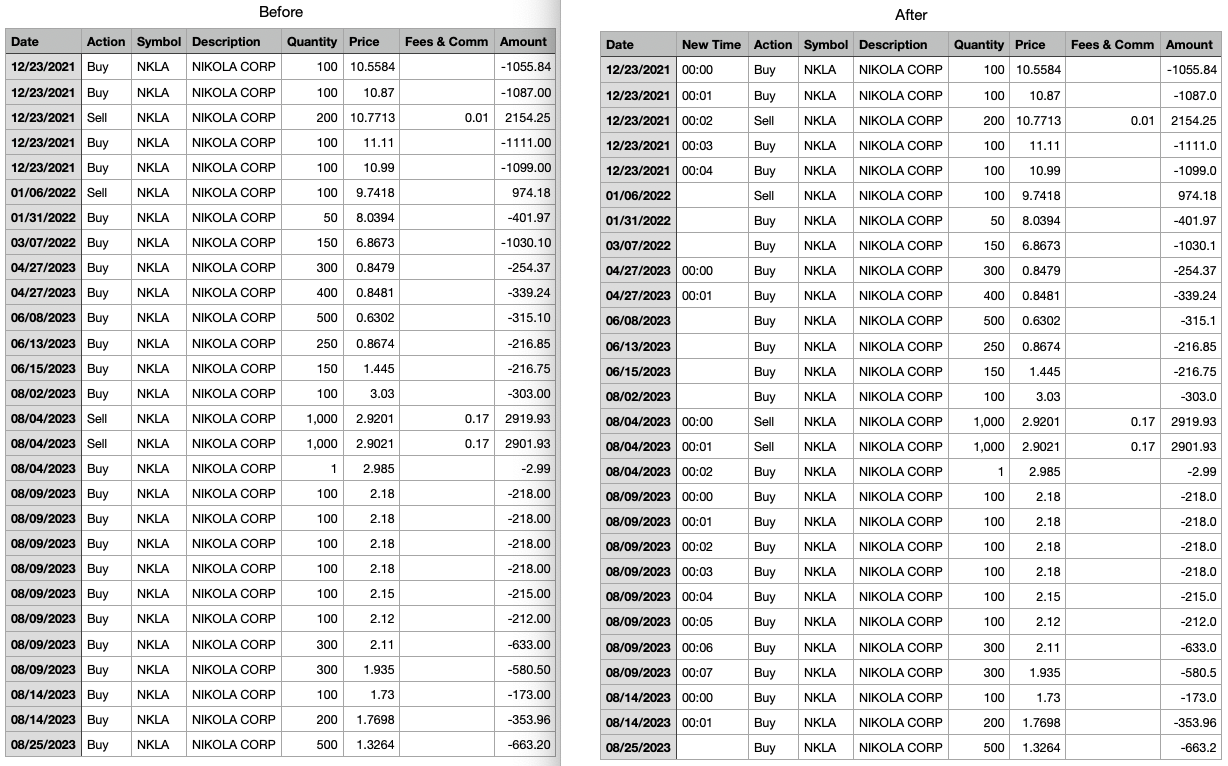
Vielen Dank für deine Antwort. Das war mein erster Versuch, und es hat auch funktioniert. Allerdings war es praktisch unmöglich, manuell hunderte oder gar tausende von Transaktionen einzupflegen. Du hast mir jedoch eine Idee gegeben: Ich könnte natürlich ein kleines Python-Skript schreiben, das meine CSV-Datei so bearbeitet, dass es für mehrere Einträge aufsteigende Uhrzeiten in eine separate Spalte schreibt, etwa 00:00, 00:01, 00:02 usw.
Dennoch bleibt die Frage: Wie ordnet PP Einträge zeitlich, wenn eine Uhrzeit fehlt und das Datum dasselbe ist? Wenn dies bisher mehr oder weniger zufällig geschieht, spräche doch– abgesehen von dem vermeintlich überschaubaren Programmieraufwand – nichts dagegen, einfach die Reihenfolge in der CSV-Datei beizubehalten. Oder gibt es andere Überlegungen, die ich übersehe?
Was glaubst Du, wie wichtig das für Deine Performance - oder für sonst irgend etwas - ist, zu welcher Uhrzeit ein Deal stattgefunden hat? Zinsen werden nicht stündlich berechnet.
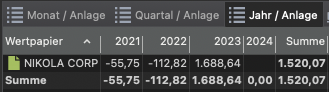
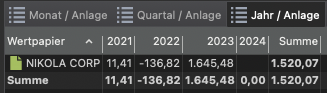
Zur korrekten Berechnung von FIFO in einem bestimten Zeitraum sehr. Siehe Screenshots unten, jeweils einmal wie importiert und einmal händisch in die richtige Reihenfolge gebracht.
Unter den oben geschilderten Bedingungen berechnet PP die Zahlungen für die angezeigten Jahre falsch. Wenn PP diese Bedingungen nicht handhaben können soll, ist das in Ordnung. Das ist eine Gestaltungsentscheidung.
Es wäre jedoch sehr hilfreich (und zeitsparend), wenn im Programm ein entsprechender Hinweis vorhanden wäre. Ich möchte nur konstruktives Feedback auf Basis meiner Nutzererfahrung geben, in der Hoffnung, dass es anderen in ähnlichen Situationen Zeit sparen könnte.
Das glaube ich Dir unbesehen. Trotzdem solltest Du Dir überlegen, was DIR das bringt. Wenn Du Uhrzeiten in Deine Performanceberechnungen einbeziehst, weißt Du so oder so nicht, was Du tust:
Ich habe absolut Verständnis dafür, wenn das Implementieren meines Vorschlags zu aufwändig ist. Soweit ich das Verstehe, arbeiten ja alle unentgeltlich neben Ihren Hauptberufen an PP.
Ich verstehe leider nicht, was du meinst, @Laura. Die oben angehängte test.csv zeigt ganz normale Wertpapierkäufe und Verkäufe (keine Leerverkäufe, Optionen, o.Ä.). Die Zeit, die PP ja unterstützt, fehlt halt, was ein realistisches Szenario für viele User sein wird. Die Frage ist doch dann, wie könnte man dieses Szenario mit abdecken, damit möglichst viele von PP profitieren können?
Mein Verständnis ist das PP finanzmathematisch auf der FIFO Methode beruht, dafür ist nun mal wichtig den zeitlichen Ablauf der Transaktionen korrekt zu erfassen, ob das nun nur mit dem Datum passiert, weil die Transaktionen mehr als 24h auseinander liegen, oder nicht ist doch mathematisch völlig irrelevant. Ich verstehe also nicht, wie ich PP falsch nutze. Aber ich lasse mich gerne aufklären.
Falls jemand in der selben Situation ist, also Uhrzeit fehlt, aber die Daten sind in der richtigen zeitlichen Abfolge in der CSV-Datei gespeichert: Hier mein jupyter notebook script. Es fügt eine Zeit-Spalte mit aufsteigenden Minuten für alle Einträge mit dem selben Datum hinzu.
import pandas as pd
from datetime import datetime, timedelta
# Load the CSV file
file_path = 'TEST.csv'
df = pd.read_csv(file_path)
# Function to generate times starting from 00:01 with increments of 1 minute for rows with the same date
def apply_times(x):
return (datetime.min + timedelta(minutes=x)).strftime('%H:%M')
# Generate a 'Time' column that increments by 1 minute for each duplicate date entry
df['Time'] = df.groupby('Date').cumcount()
mask = df.groupby('Date')['Date'].transform('size') > 1 # Only apply to dates with multiple rows
df.loc[mask, 'Time'] = df.loc[mask, 'Time'].apply(apply_times)
df.loc[~mask, 'Time'] = '' # Leave blank for single entries
# Insert the 'Time' column after the 'Date' column
date_index = df.columns.get_loc('Date')
df.insert(date_index + 1, 'New Time', df.pop('Time'))
# Save new csv
output_file_path = 'updated_TEST.csv'
df.to_csv(output_file_path, index=False)
df # Display the DataFrame to verify the new 'Time' column
Mir war so das die kleinste Zeiteinheit in PP nur der Tag ist. Die Uhrzeit wird nur optisch für die Sortierung verwendet, nicht für Berechnungen. Aber ich kann mich täuschen.
Die Reihenfolge ist relevant für die Trades (wie das Beispiel von @Jannis). Die Logik ist dabei: es wird nach Datum und Uhrzeit sortiert. Buchungen ohne Uhrzeit haben die Uhrzeit “00:00”.
Wenn Buchungen die gleiche Zeit haben, dann werden zunächst die Käufe und dann Verkäufe sortiert. Der Gedanke dabei: Trades können immer zugeordnet werden - es kann nie erste ein Verkauf und dann der Kauf kommen. Ich denke danach ist der Sortierreihenfolge in Java einfach nicht determiniert.
Für die allermeisten ist das völlig egal. Aber wenn man intraday handelt, dann ist die Uhrzeit eben doch relevant. Wenn man morgens eine existierende Position verkauft und Abends wieder kauft, dann würde PP das ohne Uhrzeit als einen intraday Trade ansehen.
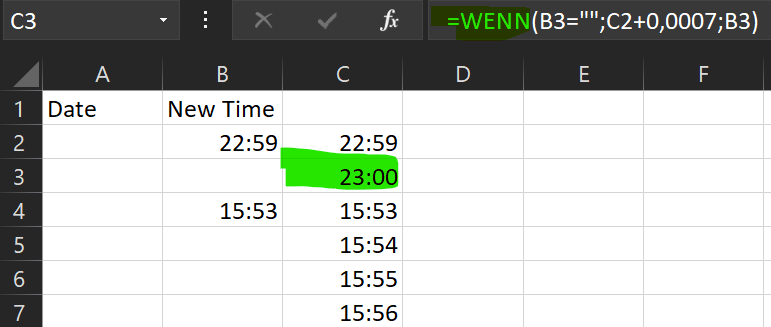
Einfach eine weitere Spalte C einfügen. Spalte B und C als Uhrzeit formatieren. Wenn eine Uhrzeit vorhanden ist wird die übernommen wenn nicht wird die aus der Zeile davor verwendet + 1Minute.
Einschränkungen bisher:
-die Formel funktioniert ab der zweiten Zeile.
-23:59 wird zu 00:00
-das Datum wird nicht beachtet
ich glaube die naheliegendste Lösung wurde noch nicht angesprochen, deswegen will ich ganz kurz fragen: Woher kommt denn die CSV Datei, und wieso hat die Datenquelle keine Uhrzeiten?