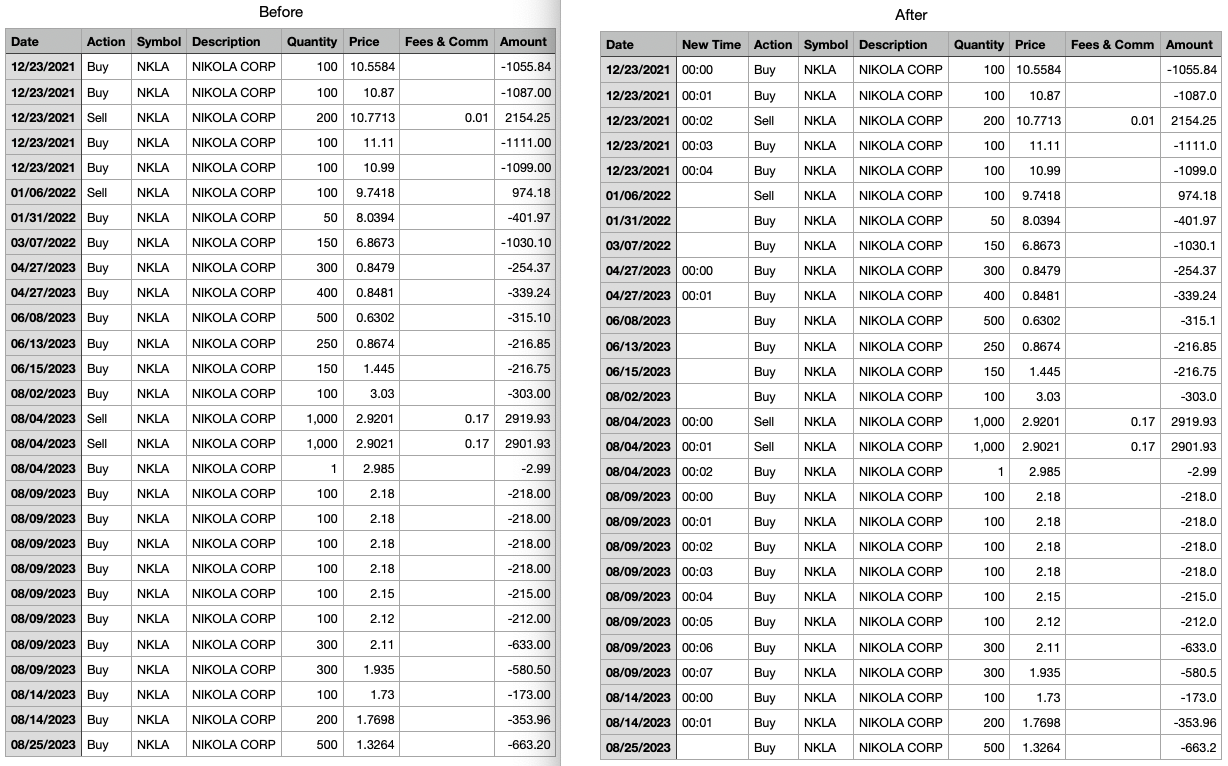
Falls jemand in der selben Situation ist, also Uhrzeit fehlt, aber die Daten sind in der richtigen zeitlichen Abfolge in der CSV-Datei gespeichert: Hier mein jupyter notebook script. Es fügt eine Zeit-Spalte mit aufsteigenden Minuten für alle Einträge mit dem selben Datum hinzu.
import pandas as pd
from datetime import datetime, timedelta
# Load the CSV file
file_path = 'TEST.csv'
df = pd.read_csv(file_path)
# Function to generate times starting from 00:01 with increments of 1 minute for rows with the same date
def apply_times(x):
return (datetime.min + timedelta(minutes=x)).strftime('%H:%M')
# Generate a 'Time' column that increments by 1 minute for each duplicate date entry
df['Time'] = df.groupby('Date').cumcount()
mask = df.groupby('Date')['Date'].transform('size') > 1 # Only apply to dates with multiple rows
df.loc[mask, 'Time'] = df.loc[mask, 'Time'].apply(apply_times)
df.loc[~mask, 'Time'] = '' # Leave blank for single entries
# Insert the 'Time' column after the 'Date' column
date_index = df.columns.get_loc('Date')
df.insert(date_index + 1, 'New Time', df.pop('Time'))
# Save new csv
output_file_path = 'updated_TEST.csv'
df.to_csv(output_file_path, index=False)
df # Display the DataFrame to verify the new 'Time' column