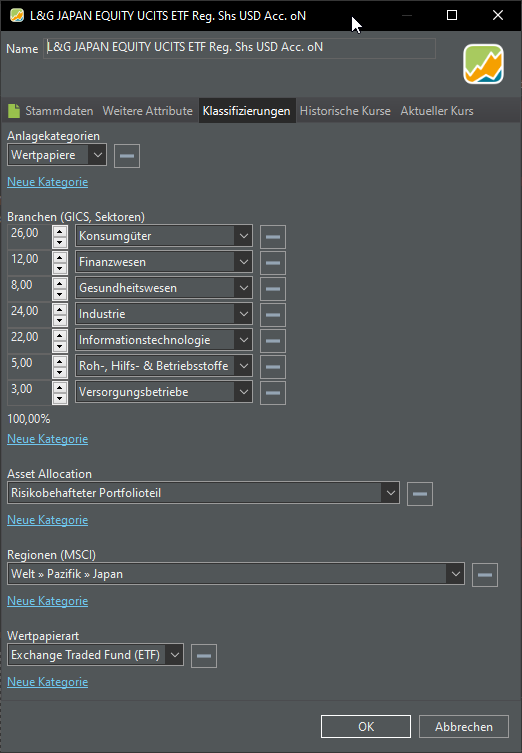
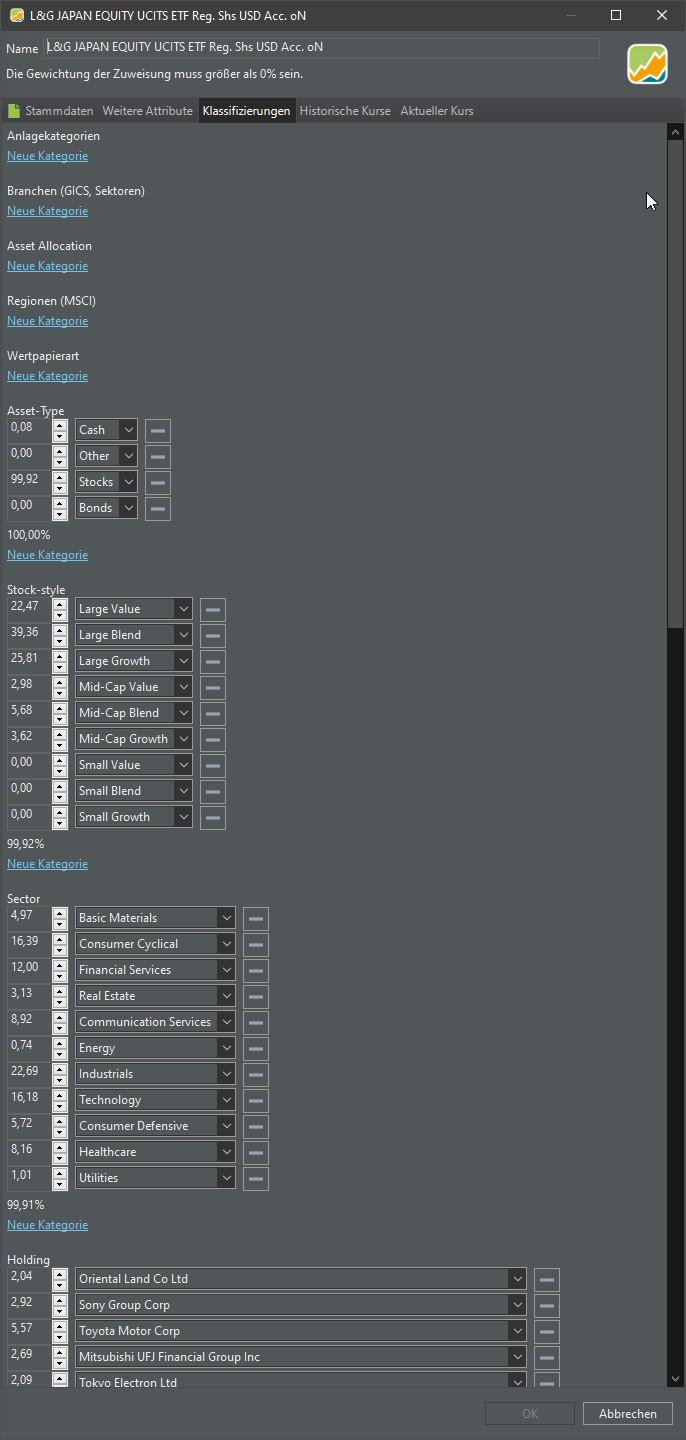
Hallo in die Runde, ich bin mir über die richtige Klassifizierung immer wieder uneins - und da es hier so ein hilfsbereites Forum mit vielen Profies gibt würde ich gern diesen L&G Japan Equity UCITS ETF euch zeigen.
Richtig, falsch, oder nur ein bisschen richtig?
Danke für jede Meinung 
Hi @MittelLos,
laut: OnePager passt das.
Am Ende kannst du es halten und machen wie du möchtest.
Wenn du Lust und Zeit auf automatische Klassifizierung hast, empfehle ich diesen Thread: Automatic import of classifications
Viele Grüße
Trotzdem gefragt: Warum zählt man Nicht-Basiskonsumgüter und Basiskonsumgüter einfach als Konsumgüter zusammen? Ist das nicht “aus Gründen” normalerweise getrennt?
1 Like
Hallo, das mit dem automatischen Import versuche ich mal wenn viel Zeit ist. Im ersten Anlauf hat es leider nicht gefunzt:
C:\xxx\PortfolioClassifier>python3 portfolio-classifier.py Comdirekt.xml
Traceback (most recent call last):
File "C:\xxx\PortfolioClassifier\portfolio-classifier.py", line 731, in <module>
pp_file.add_taxonomy(taxonomy)
File "C:\xxx\PortfolioClassifier\portfolio-classifier.py", line 589, in add_taxonomy
securities = self.get_securities()
File "C:\xxx\PortfolioClassifier\portfolio-classifier.py", line 691, in get_securities
security_h = security.load_holdings()
File "C:\xxx\PortfolioClassifier\portfolio-classifier.py", line 351, in load_holdings
self.holdings.load(isin = self.ISIN, secid = self.secid)
File "C:\xxx\PortfolioClassifier\portfolio-classifier.py", line 418, in load
bearer_token, secid = self.get_bearer_token(secid, domain)
File "C:\xxx\PortfolioClassifier\portfolio-classifier.py", line 395, in get_bearer_token
resultstringtoken = re.findall(token_regex, response.text)[0]
IndexError: list index out of range
Tja, und irgendwie ist beim Eintragen der Klassifizierung auch die Webseite verrutscht, das wird händisch korrigiert
Danke - Stefan
Wir sollten im verlinkten Thread zum Script bleiben  hilft der Übersicht.
hilft der Übersicht.
Dein Fehler schaut stark nach dem ursprünglichen RegEx aus. DIe Lösung steht wiederholt im vorletzten Beitrag des verlinkten Threads.
Viele Grüße
Krass, jetzt läuft es… wird sicherlich ne Weile laufen - bin gespannt…
Nu, ist fertig, die neue ‘pp_classified.xml’. Unglaublich was es für Genies gibt die solche Scripte schreiben.
Aber die neue Datei ist gleich 4 MB größer und benötigt wesentlich länger zum Öffnen. Es macht keine echte Freude damit zu arbeiten. Hier der Screenshot des gleichen WP:
Stefan
Hast du mal ins Fehlerlog geschaut?
Hilfe → Fehlerprotokoll anzeigen
Solltest du xml nutzen, kannst du alternativ auch das Binary Format testen.
Datei → Speichern unter → Eines der Binaries
Evtl. findest du hier: PP wird immer langsamer noch Hilfe.
Viele Grüße
Im Fehlerprotokoll werden ein paar fehlende Kurse moniert:
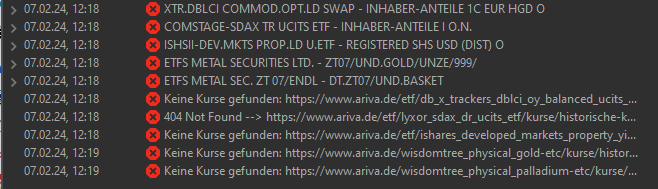
aber das kann die Ursache wohl nicht sein? Das werde ich irgendwann korrigieren.
Die Umstellung auf das Binary Format bringt auch keinen wirklichen Zeitgewinn und portfolio-classifier.py mag mit der Datei 'Comdirekt.portfolio 'auch nicht arbeiten…
Die Anpassung der ini-Datei hatte ich bereits gemacht und auf die 32GB-RAM angepasst:
-XX:+UseG1GC
-XX:+UseStringDeduplication
-Xms8192m
-Xmx24576m
Hab grad mal des Editieren eines Wertpapiers in der pp_classiefied.xml getestet:
Strg+E drücken, 60sec warten und erscheint das Fenster 
Beim Arbeiten mit der originalen .xml-Datei dauert der Vorgang max 1sec.
Mein Fazit:
Klassifizierung erfolgt manuell (das schafft Routine) und als Rentner hab ich eh Zeit ohne Ende
Das ist kein wirkliches Problem, danke für Deine Mühe…
Stefan
Ich sehe erst einmal keine wirkliche Verbindung zwischen der Klassifikation und der Geschwindigkeit.
Die Fehler im Protokoll wirken sich schon auch auf die Geschwindigkeit aus, aber gut.
Interessant zu verstehen wäre es alle mal. Aber wenn es für Dich kein Problem darstellt muss man es auch nicht strapazieren.
Viele Grüße