Video tutorial:
Extract PDF documents for debugging
Why post this topic when the wiki clearly says create new Github Issue or post in the forum (not both)? A consolidated post of PDFExtractors available or in development would be more useful.
That link is not much use when the files need to be desensitised and they are full of   which can’t normally be seen in a text editor. I passed on the recommendation from the PDFBox developer to post-process extracted text to replace all   with " ".
And this is the thread to post (update/new) text extracted from SelfWealth PDFs to.
Hello @flywire
I have fixed a few minor bugs.
Greetings
Alex
PDF author: ''
PDFBox Version: 1.8.16
-----------------------------------------
SelfWealth Limited ABN: 52 154 324 428 AFSL 421789 W: www.selfwealth.com.au E: support@selfwealth.com.au
This trade was executed and cleared by OpenMarkets Australia Ltd ABN 38 090 472 012,
AFSL 246 705, Market Particpant of ASX, CHIX and NSX.
Buy Confirmation
MR JOHN DOE Account Number: 1234567
JOHN DOE A/C Reference No: T202107011234561
1 LONG ROAD Trade Date: 1 Jul 2021
SYDNEY NSW Settlement Date: 5 Jul 2021
2000, AUS Market: ASX
WE HAVE BOUGHT ON YOUR ACCOUNT
Quantity Security Code Security Description Price +1 Consideration Currency
25 UMAX BETA S&P500 YIELDMAX 12.40 $312.50 AUD
Brokerage* $9.50 AUD
Adviser Fee* $3.12 AUD
Net Value $325.12 AUD
GST included in this invoice is $1.14
The confirmation is a tax invoice please retain for tax purposes. If this confirmation does not correspond with your records please contact us immediately at
support@selfwealth.com.au
Settlement Instructions All consideration and any information or documents required by OpenMarkets must be provided to OpenMarkets by 9am AEST on the Settlement
Date. This transaction will be settled from your linked cash account or in accordance with your instructions on the Settlement Date.
Contract Comments
Ex Dividend
* Inclusive of GST
+1 Standard Financial Rounding Applied (if applicable)
This confirmation is provided to you by each of SelfWealth and OpenMarkets. The Brokerage and Adviser fees set out in this confirmation are charged by SelfWealth.
OpenMarkets has not charged you any fees for the above transaction(s). The above transaction(s) and this confirmation are issued subject to the directions, decisions
and requirements of the operator of the relevant Market, ASIC Market Integrity Rules, the operating rules of the relevant Market, and, where relevant, the Clearing
Rules of the relevant Clearing Facility and the Settlement Rules of the relevant Settlement Facility, the customs and usages of the relevant Market and the correction of
errors and omissions. If this confirmation relates to multiple transactions, those transactions may have been completed on ASX or CHIX.”
Generated At: 5 Jul 2021 16:30:01 PM Page: 1 of 1
Ahh… now i see the problem.
As a work around… before you import the pdf’s, deactivate the historical courses… import and then re-enable.
I’ll see what can be done to solve the problem.
I’ll talk to Andreas, but it will take some time.
Note the pdf debug in this post is different to the original file linked from GitHub. The process has replaced the non-breaking spaces with spaces.
The “Sell” file was somehow corrupted - it had strange space characters which led to the patterns not working. I did remove them, but if the PDF actually creates this space characters, then…

Feel free to read on through thread yourself.
The SelfWealth PDF files have been decoded and issue investigated: [PDFBOX-5247] Space in pdf returns c2 a0 characters instead of 20 - ASF JIRA
Indeed every space is a Non-breaking_space
if you don’t like it, do your own postprocessing. It’s unusual but valid.
@buchen I think this is a good case for post-processing rather than have hidden codes in the test files. What do you think?
Add to SelfWealthPDFExtractor.java something like:
String nbsp = " "
pdfstream.replaceAll(" ", " ");
Files are very fiddly to create and error-prone with Non-breaking space.
Updated: SelfWealthBuy01.txt SelfWealthSell01.txt
From my point of view, there are two options:
- [deleted]
- do a post-processing and replace the non-breaking spaces with regular spaces - would we do this on the text output before passing it to any converter, or would this be a pre-processing specific to SelfWealth?
[and update supplied test files.]
Hello @flywire
now the PDF-Debugs show the problems… fix is done.
The previous PDF debugs did not include the characters. What is not there cannot be recognized by PP. This also means that a TestCase will pass correctly if the PDF debug was extracted incorrectly. If it is extracted correctly as in the video tutorial, then we see these characters and we can deposit them in the PDF importert.
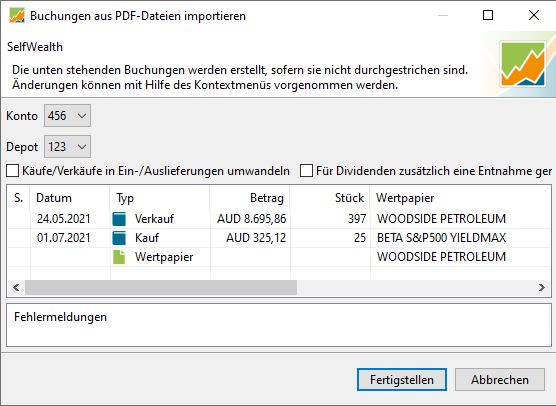
Bye
Alex
The SelfWealth PDF-Importer sets the Note to the Reference No yet it is being overwritten by the filename. Why does that happen?
Test file: SelfWealthBuy01.pdf (16.6 KB) (from tests converted to pdf with LibreOffice Writer).
Done.
Alex
Thanks Alex. The reason I asked the question is I was trying to understand the code and I couldn’t see why the filename was stored instead of the selected text. I thought it might be a standard note being introduced.
Mabe this is the root cause:
Hallo @Rafa
No, the reg expression for the note was wrong.
See in my changes: Pull request.
Match note before:
.match(" Reference No: (?<note>.*)$")
after:
.match("^.* Reference No: (?<note>.*)$")
Greetings
Alex
lol that would do it. I assume the default is:
if Note = "" then Note = filename
else Note = Note + " | " + filename
That’s probably would be good enough because the note = TransNo and filename is just userid+TransNo+.pdf.
Well, the RegEx is one thing but for my feeling, if the note is not parsable, to utilise the file name instead of feels a little bit weak
Hello @Rafa
We have made many new changes in PP. In the future, the note and the source (file name) will be separated from each other. There will be a separate column in PP for this purpose. So wait in suspense and wait for the new release.
Greetings
Alex
New contract note variant SelfWealth → Selfwealth - Selfwealth by flywire · Pull Request #2998 · buchen/portfolio · GitHub
@Nirus Can you adjust the RegEx?
Hello @flywire
I need a small PDF-Debug with one oder two transactions.
Greetings
Alex