Eine davon ist der Export in cvs-Format. Ich habe damit leider jede Menge Probleme: Die Zellen werden nicht korrekt übernommen, die Zahlen nicht als solche erkannt, die Kommasetzung mit Punkt / Beistrich funktioniert nicht.
Was ich mir wünschen würde, ist ein Export in Excel nicht als ANSII, sondern als xml / ods. Ein Export, wo die Tabelle gleich im offenen ods Format erstellt wird und kein frickeliges Datei-Öffnen mit zahllosen Versuchen nötig ist.
und idealerweise nicht nur der Export der Daten, sondern einer der Ansicht. Wenn ich etwa ein Filter auf eine Ansicht angewandt habe, sollen nicht die Daten, sondern die gefilterten Daten exportiert werden.
Wenn also eines fernen Tages Zeit übrig wäre,… bin überzeugt, dass es für viele interessant ist.
Libre Office 7.1
Es geht auch um Aufwand. Default ist gesetzt, dass ein Leerzeichen ein Zellenende ist. Da habe ich dann eine Aktie, deren Namen aus 3 Wörtern besteht. Auf einmal habe ich in dieser Zeile drei Zellen statt einer. Ja, ist alles Einstellungssache, man macht einfach den Haken raus, - doch dieses “Ausprobieren” und “Einstellen” ist eben jeden Export wieder. Da wäre eine “Datei zum Öffnen” besser, weil sie viel Zeit spart.
Meine Zahlen werden zwar geschrieben, doch LibreOffice ist unfähig, damit zu rechnen. Verwende ich sie in Formeln, so “geht es nicht”. Woran das genau liegt, weiß ich nicht. Verbrachte gestern eine erfolglose Stunde damit, es zu ergründen - bis ich aus Zeigründen(!) zum Taschenrechner griff und von einem Ausdruck manuell zu rechnen.
csv ist eben kein Import-Export-Format, sondern eine Notlösung.
Vieles möchte ich eben ausdrucken und mit einem Filzstift bearbeiten. Geht alles nicht. Etwa die Brancheneinteilung. Es wird alles derart unübersichtlich, dass man alleine fürs Druck-Formatieren “eine Ewigkeit” mit Tüfteln verbringt.
Eine gefilterte Ansicht einfach ausdrucken-können, - wäre auch ein Hit.
Entschuldige da muss ich dir aber heftigst wiedersprechen! CSV ist ein sehr weit verbreitetes Format, dass an vielen Stellen (auch im Business Bereich) genutzt wird. CSV ist ein Format das auch ideal für den Import/Export eignet! Nur Mal als Beispiel, der gesamte Austausch von Buchungssätzen zwischen ERP Systemen und DATEV läuft über CSV Dateien.
Ich würde eher vermuten, dass der Import bei Libre Office dann nicht gut ist oder du ihn falsch benutzt. Ich nutze nur Excel und kenne LibreOffice nicht. Aber bei Excel gibt es eine extra Funktion zum importieren von CSV Dateien und dann läuft das perfekt! Man muss nur die Parameter für Trennzeichen usw. richtig einstellen.
Aber was man einstellen muss hängt doch vom importierenden Programm ab und nicht vom exportierenden? Sonst kommt der nächste und will wieder ein anderes Trennzeichen.
Also entweder stehe ich auf dem Schlauch oder wir sprechen aneinander vorbei.
Beides. Du stehst auf dem Schlauch und wir reden aneinander vorbei. Mein Vorschlag war, es nicht via ASCII Zeichen kompatibel zu machen, sondern das Erstellen einer Datei in Excel Format zu ermöglichen.
csv ist “nicht super”, sondern ein uraltes ASCII-Format, eine Krücke, mit der zumindest meine Banken schon lange nicht mehr arbeiten. Überall kann ich direkt in eine Excel-Datei importieren und muss nicht über Trennzeichen und Import nachdenken.
Kurzsfassung: “Bitte um Tabelle statt Einzelzeichen”
file aktienfreunde.net_\(alle_Transaktionen_und_Dividenden\).csv
aktienfreunde.net_(alle_Transaktionen_und_Dividenden).csv: UTF-8 Unicode text, with CRLF line terminators
Nix ASCII sondern UTF-8.
Ich hab das Gefühl Du willst anderen viel Mühe machen um Dir die kleine Mühe zu ersparen mal die Bedienung eines Office-Programm zu erlernen.
Dagegen. Wenn überhaupt, dann XML als zusätzliche Option, aber nicht anstatt. CSV wird auf jeden Fall weiter gebraucht.
Beschreibe du doch ein Problem konkret indem du die ersten 2 Zeilen der CSV-Datei anonymisierst hier zeigst.
Denn in der Regel ist CSV extrem flexibel und einfach zu verarbeiten. Weil das so ist, kommt man ziemlich weit, wenn man dieses Format als Import- und Export-Format benutzt. Was für dich ein anständiges und modernes Format darstellt (OpenDocument oder die Open XML von Microsoft) ist für mich ein komplexes Format, wo ich nicht von einem Freizeit-Programmier erwarten darf, dass dieser sich mehrere 1000 Seiten Spezifikationen durchliest.
Einfach eine solche Datei entzippen und sich den Spaß mal anschauen. Aleine dies zeigt, dass ohne ein Zip-Funktion diese Formate nicht erstellt werden können. Bei CSV reicht es ein paar Formatierungs-Regeln einzuhalten und dann kann man die Variablen gleich in die Ausgabe übergeben. Dann bleibt mehr Zeit für die Programmierung, wo keine solche Abkürzung zum Ziel führt.
In der Regel reicht es beim CSV-Import das Spalten-Trennzeichen anzugeben, falls die automatische Erkennung daneben lag. Und Excel liegt gerne beim Erkennen der Kodierung daneben; zu erkenne an solchen Zeichen “ö” und “ü”). Wenn das der Fall ist, solltest du als Kodierung “UTF-8” angeben.
Mit UTF-8 kann fast jedes Zeichen dargestellt werden, womit die meisten Sterblichen zu tun haben werden (Siehe Unicode-Standard).
Deiner Beschreibung nach hast du als Trennzeichen “Leerzeichen” angehakt, was dann dazu führt, dass jedes Leerzeichen als Spaltentrenner verstanden wird. Bei mir wird dies standardmäßig nicht angehakt. Dies ist auch eher unüblich, da man mit Semikolon “;” und Anführungszeichen für Zeichenketten mit Leerzeichen bereits alle üblichen Herausforderungen umschifft hat. Da auch das Komma “,” üblich ist, reicht es bei “zu vielen Spalten” aus das Komma abzuwählen aus der Liste der als Spaltentrenner erkannten Zeichen. Aber das sieht man in der Beispiel-Ausgabe die Excel und LibreOffice direkt im Import-Dialog anbieten.
Hier ein Beispiel wie es bei mir aussieht und funktioniert. Du kannst beschreiben welche Ansicht du exportieren willst und Bsp-Zeilen davon posten.
Warum solltest du genervt sein, wenn man dir erklären möchte, dass ein universeller Export als Textdatei nunmal (ja, zum Teil vielleicht sogar leider) eben deshalb ein Standard ist, weil er rudimentär ist und deshalb von eigentlich allen Programmen, bei richtiger Anwendung, importiert werden kann.
Selbst bei mir im Lab nutzen alle Maschinen einen Datenexport als CSV-Datei. Das klappt sogar systemübergreifend und ist nicht Programmgebunden.
Einzige Hürde für den Anwender ist es, sein eigenes Verarbeitungsprogramm zu kennen, um den Import korrekt ablaufen zu lassen.
Das aber ist ungemein weniger Aufwand, als obiges anzupassen.
Es besteht also absolut kein Grund, “leicht genert” reagieren zu müssen.
Ich benütze LibreOffice seit Jahren und habe keine Probleme daten von PP zu importieren.
Falls in den Daten nummern sind die als % ausgedrückt sind wie “17.85%” muss man “Detect special numbers” ticken. Mein LibreOffice ist in English aber mit dem beigefügten bild bist sollte klar sein welches Feld getickt sein muss.
Nichts verkehrt mit .csv exports
Leute, wenn Ihr KEINE Probleme habt, dann reizt Ihr das geniale PP entweder nicht aus oder Ihr habt selbst kaum Aktien, die Ihr damit verwaltet.
OhBoy: Natürlich kann ich den Haken bei Semicolon auch alleine reinmachen. Natürlich weiß ich, dass bei “Space” der Haken rauskommt. Es geht doch nicht darum, ein Text-File in Excel zu bringen!
Bitte nur an jene, die auch wirklich aktiv PP BENUTZEN: Exportiert Eure Kategorisierung “Branchenverwaltung” einmal in Excel. Ja bitte, das geniale Semikolon angehakt. Und jetzt? Wenn Ihr WIRLICH damit arbeitet, erschlagen Euch jetzt 10-20 Din A 4 Seiten Excel Format.
Wenn es hier noch immer “ganz einfach” und kurz ist, dann habt Ihr es nicht richtig benutzt oder keine Aktien zugewiesen, weil Ihr keine oder nur wenige damit verwaltet.
Darüber hinaus findet Ihr für jede Ebene eine eigene Zeile und für jede zugewiesene Aktie eine Zusatzzeile. Bei Dir nicht? - Dann hast Du keine Aktien zugewiesen oder kaum Aktien, die Du mit dem mächtigen Werkzeug verwaltest. Drucke es aus und Du hast einen Stoß Papier mit zahllosen Doubletten, Spalten, die Du gerne woanders hättest und die sich nicht auf die Ebenen beziehen, die Du bearbeiten willst.
Will man dann seine Oberebenen-Zuweisungen in Excel bearbeiten und etwa nur die obersten 2 Ebenen ausdrucken, dann geht das einfach nicht! Oder man muss es stundenlang bearbeiten. Wenn Ihr das nicht müsstet, dann schöpft Ihr das Potential des genialen PP nicht aus.
Was spricht dagegen, sich zu WÜNSCHEN ein zusätzliches Format als xls / ods zu haben wie es von zig Banken und Brokern angeboten wird? GERADE wenn man programmiert, kann man zusätzlich zum Zeichen-Wurschteln noch die odf-Schnittstelle benutzen. Die ist doch viel mächtiger als Buchstaben. Da ich selbst mit dieser Schnittstelle arbeite, kann ich meinen Source-Code auch gerne zur Verfügung stellen.
Wer also “keine Probleme mit dem Export hat”, dem kann ich nur ans Herz legen, den Beitrag von Andreas Buchen zur Kategorisierung mit Branchen zu lesen. Denn es macht Euch wohlhabend, es richtig einzusetzen.
an dieser Stelle an Andreas: DANKE. Du hast das beste Werkzeug entwickelt, das es weit und breit gibt und es ist kostenlos. Auch wenn offenbar manche es noch nicht ausreizen.
Sorry bei dem Ton steige ich hier aus. Ich wollte dir nur helfen. Nur noch so viel: Wenn es doch so einfach ist und du alles dafür schon hast, dann setz es um, ist ja Open source…
PP exportiert und LibreOffice importiert die Daten richtig. Ja es sind sehr viele Zeilen.
Wenn Sie die Daten als .xls haben wollen dann speichern Sie einfach das importierte .csv als .xls File und laden das danach wieder in LibreOffice. Was das einen unterschied macht kann ich mir nicht vorstellen.
Bitte beschreibe ganz genau was du erreichen willst. In erster Linie arbeitest du dich an den Besonderheiten des CSV-Formates ab, die du für unübersichtlich und aus der Zeit gefallen hälst. Du kannst problemlos recht haben, aber jedes Format hat seine Stärken und Schwächen. Wenn du also so allgemein CSV schlecht machst, ist es acuh einfach zu argumentieren wieso CSV das beste Format für den universellen Export ist.
Ich tue mich schwer zu verstehen wo du genau hin willst. Ich lese heraus, dass du die Branchen-Ansicht filtern möchtest und mit dem Ergebnis mit seinen vielen Zeilen nicht zufrieden bist. Bis dahin komme ich mit.
Nur was für eine Ansicht möchtest du erreichen?
Wenn ich dich richtig verstanden habe, willst du nur die erste 2 Hierarchie-Ebenen als Ergebnis?
Wenn ich die Branchen-Ansicht als CSV exportiere und in Excel/Calc importiere, kann ich den AutoFilter über die Tabelle legen. Dann im Spalten-Kopf “Ebenen 3” nach “Feld ist leer” suchen und ich habe als Ergebnis meine Branchen-Verteilung nach Branche aufgeschlüsselt.
Den AutoFilter kennen viele in Excel auch unter der Funktion “Als Tabelle formatieren”, die dann einen Filter in den Tabellen-Kopf eingebaut und gleichzeitig die Tabelle mit einem netten Design aufbübscht. Das Ergebnis ist schöner, aber im Kern dassselbe.
Ist es das was du haben möchtest? Oder etwas anderes?
Dann bitte präzise beschreiben, damit wir dich und den Problem verstehen können.
Noch ein paar Worte zum Thema “Programmieren”:
Große Open Source-Projekten bekommen Code von sehr vielen verschiedenen Programmieren. Derjenige, der neuen Code schreibt, muss nicht derjenige sein, der am Ende darin Bugs findet und beseitigt.
Wenn also jemand eine neue Funktion hinzufügen möchte, dann muss diese am Ende auch “wartbar sein”. Und alte Hasen verstehen darunter meistens etwas ganz anderes als die Jüngeren.
“Technische Schulden” kann man das nennen. Damit gemeint ist, dass jeder weiß, dass der alte Code nicht mehr den aktuellen Empfehlungen entspricht und dringend komplett überarbeitet gehört nach dem neuen Programmier-Prinzipien. Aber weil niemand Zeit dafür hat, wird der Code langsam immer schwerer zu verstehen. Irgendwann macht es keinen Spaß mehr und man fängt bei Null an. Und hat als Dank die Erwartung der bisherigen Nutzer, dass man “mal eben” den alten Funktionsumfang nachprogrammiert. Woran dann spätestens auch die Ambitioniertesten scheitern.
Du kannst gerne Code-Vorschläge einreichen. Je umfangreicher, desto präziser solltest du vorab kommunizieren wieso du das für eine sinnvolle Verbesserung hälst.
Allerdings bin ich da skeptisch. Was du als “Zeichen-Wurschteln” abtust, ist - sauber umgesetzt - eine ebenso akzeptable Art eine Lösung zu programmieren wie heute übliche Programmieransätze. Den Meister erkennt man am Stil und nicht, ob seine Formate im Text- oder im Binärformat vorliegen.
Und gerade der Banken-Bereich ist eher zurückhaltend bei Änderungen in seinen Kern-Systemen für Geld-Transaktionen. Im Kern wirst du alles finden, aber nichts, was einen alten Mainframe aus der Bahn werfen könnte. XML wird gerne verwendet. Auch gerne mit UTF-8, aber bitte nur mit dem “Latin Character Set”.
(Ein echter Insider-Witz diese Formulierung )
Quelle: Seite 5 - Fußnote 2 im Dokument “Anlage_3_Datenformate_V3.4.pdf”
Wenn du nach meinem Versuch noch Probleme hast, beschreibe was ich übersehen habe und was du genau erwartest.
Wenn für dein Problem eine gute Lösung gefunden wurde, kann die Idee immer noch aufgegriffen werden von den aktiven Entwicklern oder du kannst dich einbringen.
Naruhodo: Danke für Deine Anwort. Ich habe zwei Aufgaben, von denen ich ganz frustriert bin (sorry an jene, die von meinem Frust etwas abbekommen haben, obwohl sie guten Willens waren)
Das eine ist eine Aufgabe, die jeder Händler haben wird, der kein Zocker ist:
Das “Ausgeben seiner offenen Positionen” und wohl auch deren Ausdruck. Durch die Vielzahl meiner Vertragspartner bleibt mir hier zur Zeit nur der Excel-Sheet, den ich manuell führe. Jeder Vertragspartner kann wahlweise via csv, xml oder pdf ausgeben (und alle Zahlen weren in Calc als solche erkannt!). Das kann ich dann zusammenkopieren, - doch es ist ja ätzend. Genau dafür habe ich ja PP, damit ich meine Positionen AUS EINER HAND verwalten kann.
Mit Screenshot 1 und Screenshot 2 zeige ich Dir, welche Probleme ich damit habe. Sollte ich es wegen der slow-motion nicht hochladen können, beginne ich eine neue Thread. Siehst Du also binnen 10 Minuten nach diesem Posting keine Grafiken, bitte nach neuem Threads suchen.
Wenn ich mehrmals die Woche meine Positionen umschichte und verändere, will ich sicherlich nicht in Summe ein paar Stunden mit Kopieren und Formatieren zubringen.
Mein Wunsch daher in einem Term: “Zeige mir meine offenen Aktienpositionen” (und das bitte alphabetisch sortiert).
Also einfach ein Übersichtsblatt, das jeder leidenschafltiche Händler mit sich rumtragen sollte. Und wer sich beim Traden-Lernen die Augen ruiniert hat: auf Papier.
Die andere Aufgabe ist das Diversifikationsmodell.
Einerseits will ich es ebenso drucken, andererseits auch mit den stochastischen Formeln bearbeiten könne, die Excel / Calc anbieten.
In Screenshot 3 zeige ich Dir, was mir zuviel Zeit abverlangt und auch, wie ich es gerne drucken würde können. Will man ausgiebig damit arbeiten, braucht man es einfach auch auf Papier.
Hinweis an Leidensgesnossen: Als Workaround verwende ich zur Zeit “Screenshot” (also die Druck-Taste). Da man zig Screenshots braucht für eine Modelldarstellung, ist auch das mühsam ohne Ende. Geht aber wenigstens.
ad Open Source: Natürlich war meine ERSTE Idee, den Code anzusehen und der Gemeinschaft zur Verfügung zu stellen. Ich lud ihn also herunter, - und er ist mir zu fremd. Ich komme aus der Windows Welt und ganz anderen Code-Typen. Ich komme in absehbarer Zeit nicht zurecht damit. WENN ich schon soviel Zeit investieren würde, würde ich alles in eine Firebird-Datenbank geben, doch dafür kann ich zu wenig C, um es umzusetzen. Der heruntergeladene Code erschlug mich förmlich.
Wofür so ein “Export von 2 Ebenen als Tabelle” noch gut wäre: Wir könnten ihn TEILEN und hochladen. So eine Diversifikation ist sehr viel Arbeit. Es wäre doch spannend, so einen Export unter Händlern zu diskutieren und die Vor- und Nachteile zu erwägen. Wohin etwa gehören Düngemittel? In Agrar oder in Chemie? Macht eine Aufteilung 50:50 Sinn? uvam.
Hingegen den kompletten Sheet hochzuladen, wäre unangemessen. Denn das würde bedeuten, dass man seinen Kontostand öffentlich machen müsste.
Daher mein Wunsch in einem Term: “lasse mich die obersten 2 Ebenen exportieren / drucken”
So long, ich probiere jetzt das Upload der Screenshots.
Exkurs: Was ist ein csv Format?
(die Darstellung verkürzt pointiert und ist damit teilweise nicht ganz richtig)
Dazu eine Vorfrage:
Was ist ein Bit und wie viele Informationen können wir darin speichern?
Ein Bit ist bekanntlich die kleinste Einheit eines Computers und wir können 2 Informationen speichern: Strom oder nicht Strom. Wer dazu gerne ein Bild hätte, lege sich einen Kuli neben den PC (oder ein Streichholz) und drehe ihn mit der Spitze einmal zu sich und dann um PC: 2 Möglichkeiten.
Hätten wir so einen “Computer” mit einem Bit, - so könnte der nicht bis 3 zählen.
Daher kam Konrad Zuse 1930 auf die Idee, einige Bits in Serie zu schalten:
Bitte legt einen zweiten Kuli dazu und probiert es aus:
Wer 2 bits hat, kann - genau - 2 HOCH 2 Informationen speichern, also 4.
der geniale Zuse fragte sich:
Wie viele Infos müsste man erst bekommen, wenn man gleich 8 bits in Serie legt?
Genau: 2 hoch 8.
Wer etwas Kopfrechnen kann, wird schnell wissen: Das ist 256.
Und wer so verspielt ist wie ich, hat jetzt mit 8 Kugelschreibern visualisiert, was ein Byte ist.
Habt Ihr Euch je gewundert, warum in Netzwerkadressen oder Subnetzwerken so oft steht “255”?
Das ist von inkl. 0 bis 255 gezählt genau ein BYTE an Speicherplatz.
Mit anderen Worten: Ein Byte besteht aus 8 bits und kann daher 256 verschiedene Informationszustände haben.
Jetzt dachte man sich: Was ist, wenn wir für jeden Speicherzustand einen Buchstaben oder ein sonstiges Zeichen fingieren? - Damit war der ASCII-Code geboren. Ein System, dass in einem einzigen Byte Speicherplatz genau ein Zeichen speichern kann.
Das kann sein ein großes A oder auch ein Bindestrich oder ein kleines x.
In Summe jedoch nicht mehr als genau 256 Möglichkeiten.
Das war zwar total speichereffizient, doch die zu speichernden Zeichen waren einigen nicht so günstig. So erfanden sie andere Zuordnungen: ANSII, UTF-8 uvam. Wobei keines davon “moderner” ist in engerem Sinn, sondern vielmehr der altes Sauerier aus den 1960er namens ASCII verschiedenfarbig lackiert wurde.
Ein System, das solche ein-Byte Zeichenketten in Serie speichert (und gruppiert) ist csv. Da selbst die Gruppierungsinformation nur eines von den 256 Zeichen sein kann, ist es oft mehrdeutig. Dummerweise wissen wir nicht mal, ob es sich orientiert an ASCII, ANSI, UTF-8 oder der Frau Holle. Es hat eben nicht mehr als eine Byte-weise Darstellung.
Dadurch, dass 1-Byte-je-Zeichen so alt ist, kann es jedes Programm lesen. Kann es eines nicht, benennt die Datei um in *.txt und schon geht es. Es ist nicht mehr als 1 Byte = 1 Zeichen.
Wenn wir jetzt etwas “in csv exportieren” bedeutet das, dass wir die Informationen eines Programmes oder einer Darstellung auf 256 Einzelzeichen eindampfen. Also so wenig, dass man seit den 1960er damit schon nicht zu recht kam und deshalb den ASCII-Code ständig “neu erfand” bzw. “anders bunt lackierte”. Dabei geht jede Menge Information verloren! Denn mit 256 Zeichen kann man eben sehr, sehr wenig darstellen.
Werden jetzt diese 256-Zeichenketten in irgendein Progamm importiert, “kann” es jedes Programm lesen. Klar. Ist ja archaisch. Doch welches Programm diese Zeichen zufällig wieder zu einer brauchbar formatierten Datei zusammensetzt, das ist ziemliche Glückssache.
Und die Moral von der Geschicht: Vernichte Deine Formatierungsinformationen nicht.
Da sich die Beschwerden der Anwender zu den meisten Programmierern herumgesprochen haben, bieten heute fast alle modernen Anwendungen neben csv als Universalschnittstelle, auch Exportmöglichkeiten an, die eben nicht derart viele Informationen vernichten.
Dabei ist xls sehr probat.
xls wird von Excel gelesen, ist kompatibel zu ods (OpenOffice und Verwandte) und stellt komplette Tabellen dar. Es weiß auch ob “5” als Buchstabe oder Zahl interpretiert wird. Programmiertechnisch gibt es Schnittstellen in dieses Format, das komplette Elemente wie etwa ganze Spalten lesen kann.
xml dagegen ist abwegig als Export, weil es ein Programm braucht, dass seine subjektiv vergebenen Formatierunsinfos lesen kann. Sprich: xml ist von einem konkreten Programm abhängig, wie etwa PP, dessen gesamte Information in XML gespeichert sind.
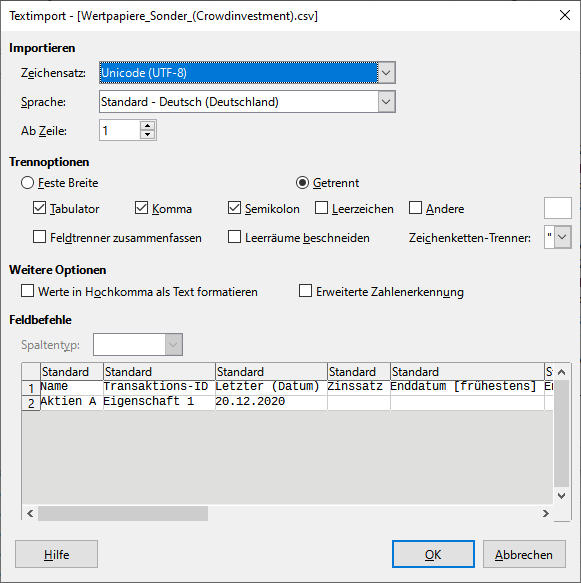
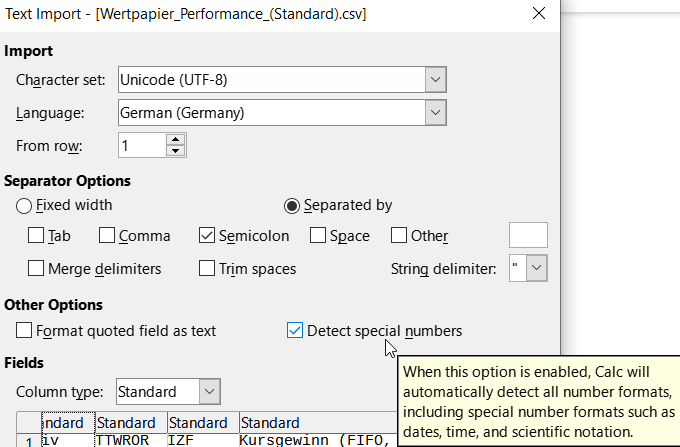 bist sollte klar sein welches Feld getickt sein muss.
bist sollte klar sein welches Feld getickt sein muss.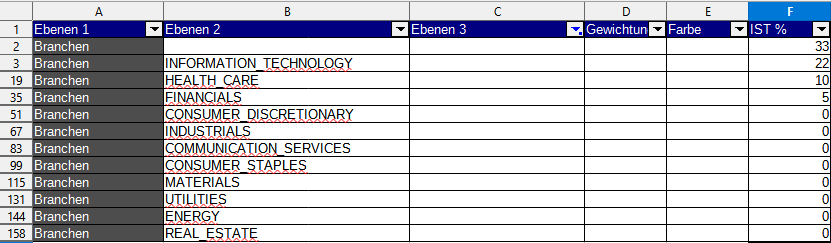
 )
)