Leider nein, das gleiche Problem hatte ich auch schon nachgeschaut. Ist eine Limitierung von PP.
Hallo @pat-s,
hast Du irgendeine Idee für einen Workaround?
@AndreasB denkst es ist moeglich hier eine groessere Nachkommazahl zuzulassen?
Viele Grüße
Thomas
Habe mein Glück mit den Python Tool auch mal versucht und das letzte Jahr importiert. Bei mir kommen allerdings völlig sinnfreie Ergebnisse in PP zustande. Obwohl, wie von @Thomas12 angemerkt, viele Buchungen 0 ergeben wegen der Nachkommastellen, steigt mein Saldo auf ungefähr das 5-fache der wirklichen Einlage. Es liegt wohl daran, dass alle Rückkäufe mitgezählt werden.
Hallo @networx,
ich wollte heute auch die Werte Einpflegen, leider ist der aktuelle Output von Mintos (in de und en) nicht mit dem Tool umwandelbar. 
Hast Du es hinbekommen?
Viele Grüße
Thomas
Peercasso: Nein, kenne ich nicht (ist auch ein Windows-Only-Programm)
Du trägst also Deine P2P-Plattform-Login-Daten in eine closed-source Anwendung ein, welche man von einer impressumslosen Seite lädt? Man könnte das mutig nennen.
2 Likes
Hallo zusammen,
nun, was soll ich sagen. Es gibt seit Oktober  2020. Ein neues Release des Tools PP-P2P-Parser V1.2.1. Damit funktioniert die Umwandlung in das PP kompatible Format wieder.
2020. Ein neues Release des Tools PP-P2P-Parser V1.2.1. Damit funktioniert die Umwandlung in das PP kompatible Format wieder.
Ein tolles, kleines und vor allem Opensource-Tool, dass sich perfekt mit PP versteht.
Viele Grüße
Thomas
1 Like
Kann ich nicht bestätigen. Die Version hatte ich versucht, mit den oben beschriebenen Problemen.
Ist ehrlich gesagt auch alles nicht sonderlich komfortabel. Wenn man sich zu helfen weis bekommt man das irgendwie hin aber die Installation von Python, Yaml etc. kann man doch keiner mitteleuropäischen Hausfrau zumuten.
Frage wäre wie viel Bedarf es an einer Integration gibt. Evtl. opfert sich dann jemand zu Erstellung einer Vorlage oder ähnlichem.
Sehr mutig @Paolo …
- Kein Impressum
- Protonmail Adresse, nicht nachverfolgbar (anoyme E-Mail, der Anbieter speichert kein persönlichen Daten/IP)
- .com Domain über Porkbun LLC (spezialisiert auf WHOIS privacy ->> Inhaber der Domain nicht nachverfolgbar)
Der Anbieter verschleiert aktiv seine Identität. Nun kann man sich fragen wieso …
2 Likes
Ich nutze es seit mehreren Monaten. Hin und wieder sind fixes nötig da der P2P provider seine Berichte ändert.
Sicher ist es nichts für jeden, da man ein bisschen Verständnis im Umgang mit code braucht.
Ist aber völlig ok - das gleiche trifft auf Excel und andere Dinge zu.
Ich komme z.B. mit so etwas besser klar als mit jeder Excel Tabelle.
Bei Problemen kannst du einen „issue“ eröffnen und bekommst evtl. direkte Hilfe.
Ansonsten ist es einfach ein Angebot und es steht keine Versprechung dahinter.
War auch weniger eine Kritik am Tool (ich finde es ja toll, dass sich jemand die Mühe macht) als eine Feststellung.
Man kann halt nicht bei jedem, nur weil er PP nutzt, tiefergehende IT-Kenntnisse voraussetzen. Daher denke ich, dass diesen Nutzern langfristig ein funktionierender Import-Filter in PP mehr hilft. War nicht eh mal ein konfigurierbarer Importer angedacht? Aktuell kann man ja leider nur die Spalten aber keine Zeilen definieren.
Klar, dafür ist PP ja gedacht - solche Sachen zu vereinfachen. P2P importe sind tricky weil es jeder anders macht (gut, dass könnte man bei Aktienkauf-PDFs auch sagen) und der Markt noch nicht so bekannt ist wie der klassische Aktienmarkt.
Ich bin bei manchen Anbietern dazu übergegangen einfach eine monatliche Summe zu verbuchen - da es hier ja keine täglichen Zinseszinseffekte gibt die man verpassen könnte, sehe ich aktuell kein großes Problem.
Mit der Methode habe ich dann trotzdem die monatliche Übersicht und den Wertanstieg im Portfolio verbucht.
Hallo zusammen,
ich habe versucht mit der aktuellsten Import Version von Kalu
meine Daten von Mintos zu importieren.
Das Problem ist allerdings, dass PP die Beträge nicht richtig verarbeitet. So sieht im ersten Schritt der CSV-Import aus:
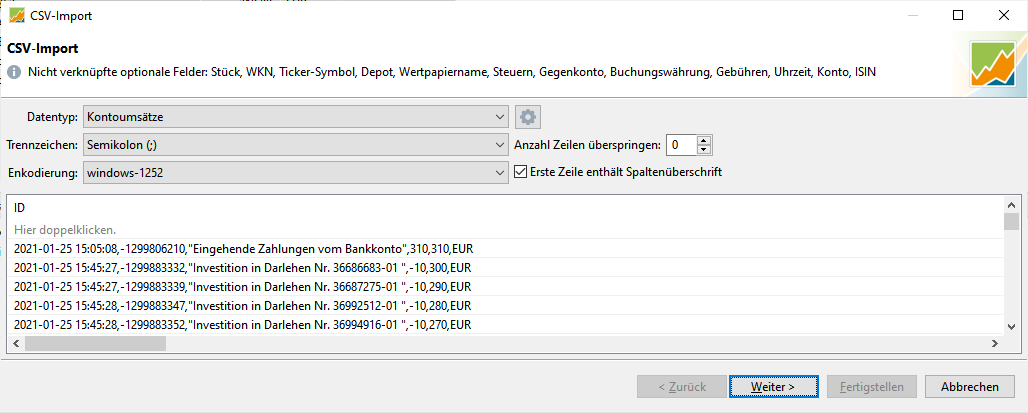
Im nächsten Schritt möchte PP aber statt den richtigen Beträge immer 2.021 EUR buchen.
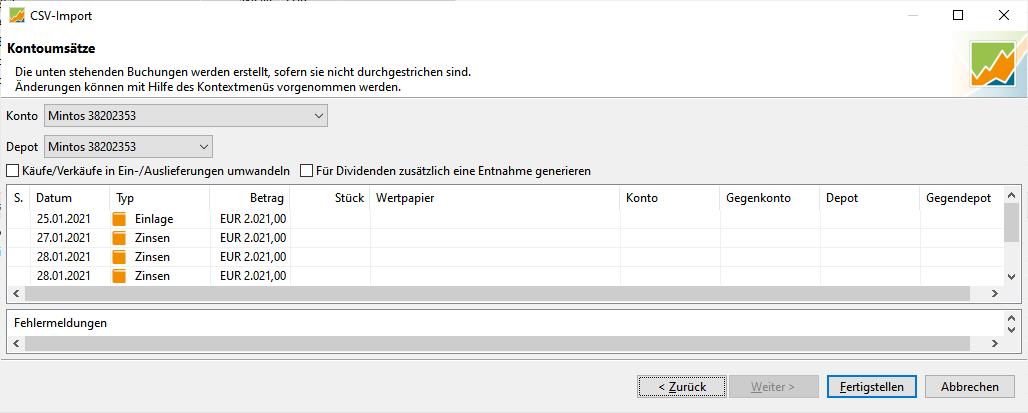
Kann mir hier jemand helfen und sagen, was falsch läuft?
Danke und Gruß
„Trennzeichen: Semikolon“
Etwas anderes als Trennzeichen Semikolon funktioniert nicht.
Oder was genau meinst du?
Das Trennzeichen in deiner Datei ist ziemlich eindeutig ein Komma.
Ja das ist richtig. Aber weder von Mintos noch durch die Import_V1.8 Datei bekomme ich eine csv mit Trennzeichen Semikolon
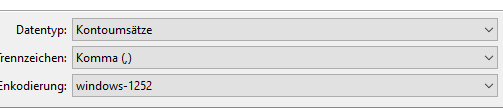
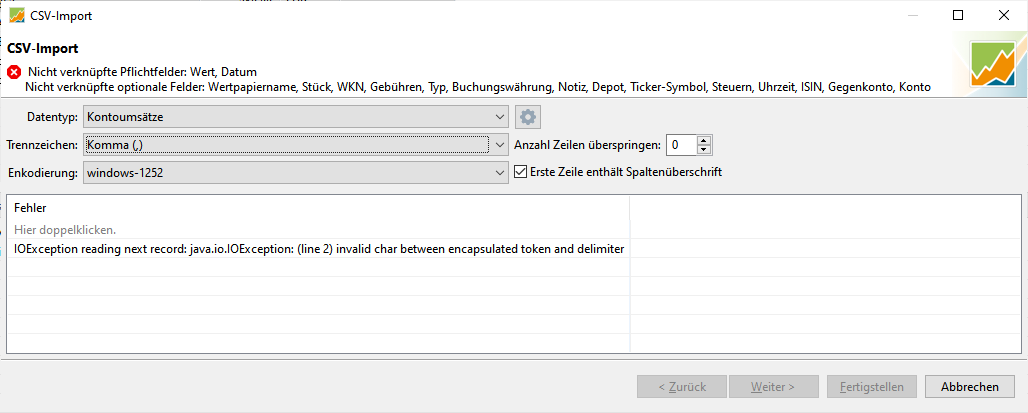
Einfach bei der CSV Import das Trennzeichen von Semikolon auf Komma ändern
Hallo zusammen,
das Problem von CrusherXP ist, dass Mintos die Reports aktualisiert hat, und das Import-Tool nicht mehr ohne weiteres funktioniert. 
Mintos hat die Beschreibungen geändert, und zusätzlich teilen die die CSV Datei nun mit Kommata.
Da wir dies in dem Excel-Tool nicht auswählen können, wird dort die fehlerhafte Datei für PP erstellt, die dann natürlich nicht rein geladen werden kann.
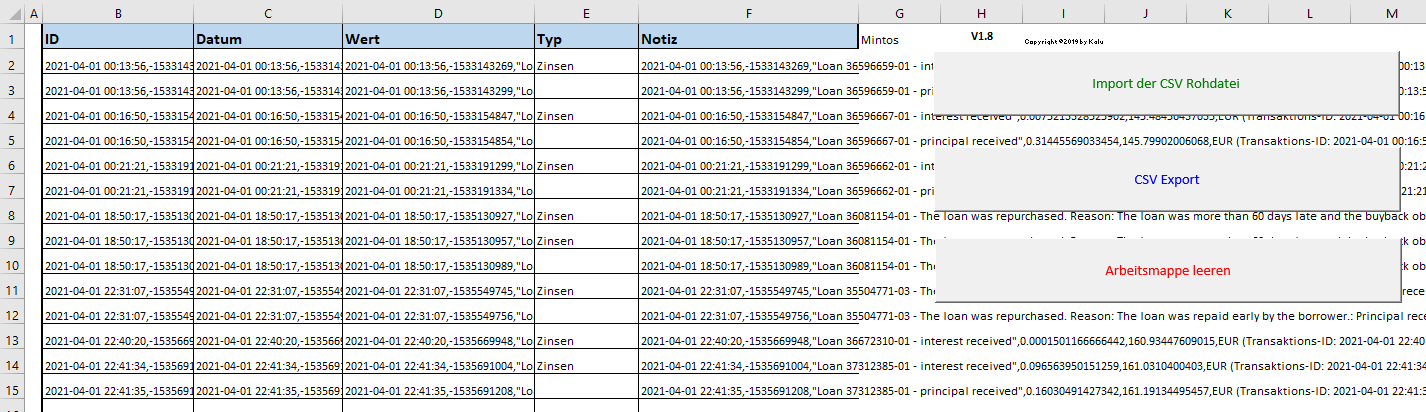
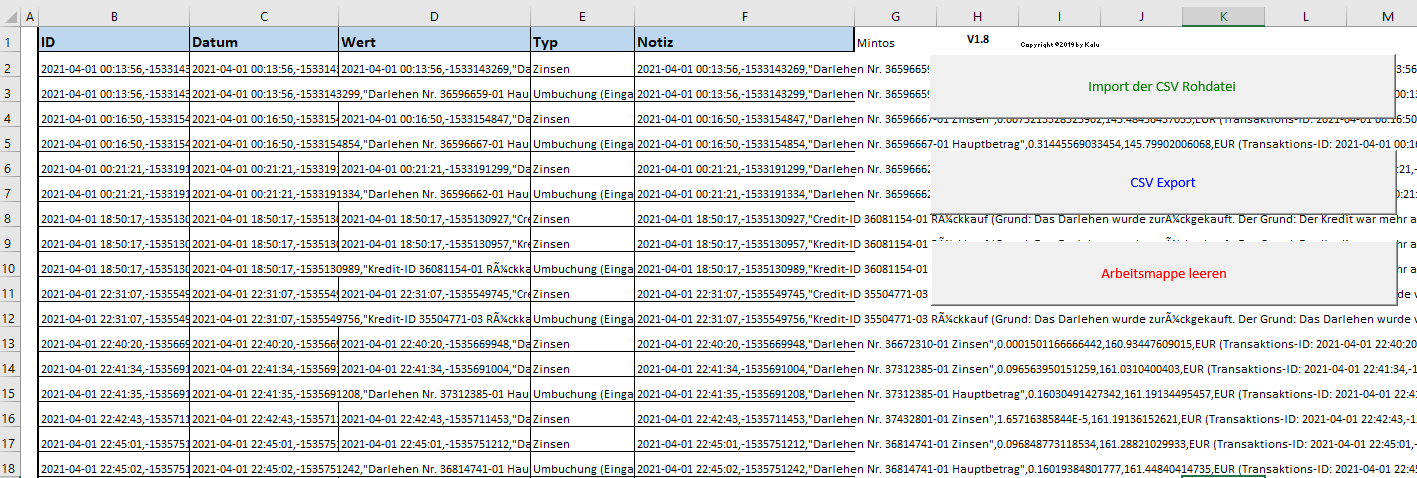
@CrusherXP
das Problem lässt sich umgehen, wenn Du die exportierte CSV Datei von Mintos mit einem Text Editor öffnest, und alle Komma ggen ein Semikolon tauschst. 
Das ist etwas umständlich, aber auf die schnelle klappt das.
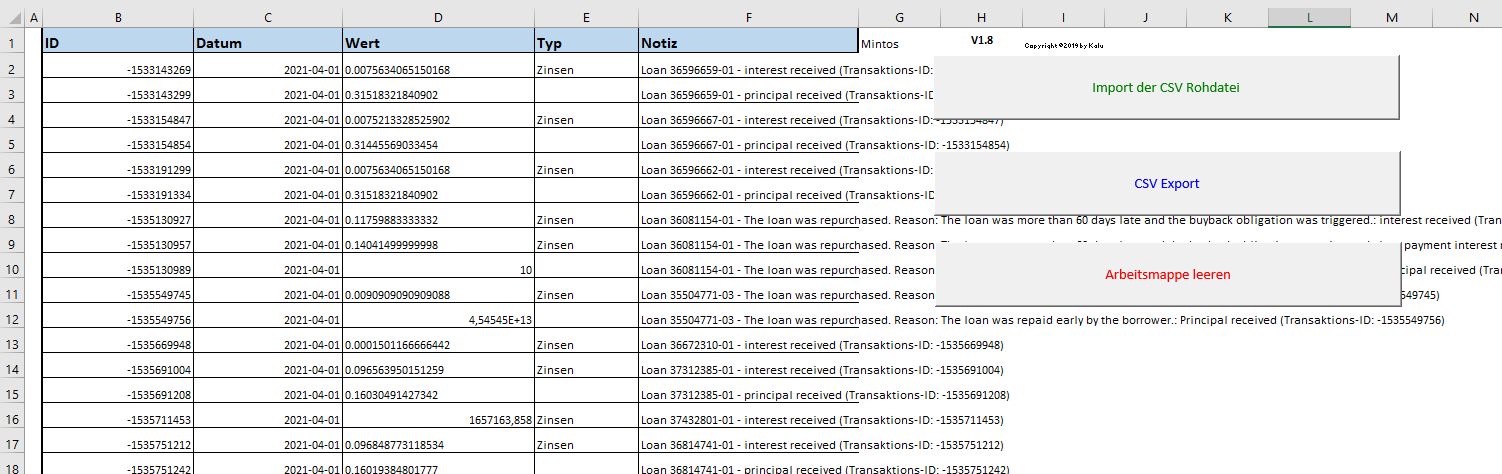
VG
Moin,
ich habe mir die Mühe gemacht und mir zwei kleine Bash-Skripte geschrieben, die mir die XLSX von Swaper und die CSV von Neofinance so konvertieren, dass ich den CSV-Import in PP nutzen kann.
Für das Swaper-Skript sind die Python-Tools xlsx2csv und csvkit notwendig. Für das Neofinance-Skript verwende sed und auch csvkit. Es geht auch ohne sed. Doch dann müssen vorher die ersten drei Zeilen manuell entfernt werden.
Das ganze sieht dann für Swaper so aus:
#!/bin/bash
#This script convert xlsx of swaper account statement for csv import to portfolio performance.
#Just interests, withdrawals and fundings are converted to csv. But you can adjust this.
#This script use sed, the python tools xlsx2csv and csvkit it must be installed.
#Usage: ./script.sh downloaded-statement.xlsx
# Array with strings to find inside of origin xlsx
arrFind=(INTEREST WITHDRAWAL FUNDING)
# Array with columns of origin xlsx for search and copy
arrColOrigin=("Transaction type" "Booking date" "Amount")
# Arrays with columns and values which are nessecary & useful for csv import in pp
arrColNew=(Typ Wert Datum)
arrValNew=(Zinsen Entnahme Einlage)
# Array with helper files and at least final output file
arrFile=("interest.csv" "withdrawal.csv" "funding.csv" "out.csv" "swaper.csv")
for i in {0..2}
do
#For loop references variables inside of arrays i.e. interest -> Zinsen -> interest.csv
#should on same position inside of the different arrays.
#Scheme: Convert input xlsx to csv | find inside of selected column, selected string |
#cut selected columns |
#add new column (type) with selected value for each row > write to file
xlsx2csv "$1" | csvgrep -c "${arrColOrigin[0]}" -m "${arrFind[i]}" |
csvcut -c "${arrColOrigin[1]}","${arrColOrigin[2]}" |
csvstack -n "${arrColNew[0]}" -g "${arrValNew[i]}" > "${arrFile[i]}"
done
# Merge separately helper files to one file
csvstack "${arrFile[0]}" "${arrFile[1]}" "${arrFile[2]}" > "${arrFile[3]}"
# Adjust head row | format delimiter > write to final output file
csvsql --query "select [${arrColOrigin[1]}] as "${arrColNew[2]}", "${arrColNew[0]}", \
"${arrColOrigin[2]}" as "${arrColNew[1]}" \
from ${arrFile[3]::-4}" "${arrFile[3]}" |
csvformat -D ";" > "${arrFile[4]}"
#Remove helper files.
rm "${arrFile[0]}" "${arrFile[1]}" "${arrFile[2]}" "${arrFile[3]}"
Und für Neofinance sieht das so aus:
#!/bin/bash
#This script convert xlsx of swaper account statement for csv import to portfolio performance.
#Just interests, fees, tax, withdrawals and fundings are converted to csv. But you can adjust this.
#This script use sed and the python tool csvkit it must be installed.
#Usage: ./script.sh downloaded-statement.xlsx
# Array with strings to find inside of origin xlsx
arrFind=("palūkanų grąžinimas" "Money transfer" "Money deposit" "GPM" "vėlavimo palūkanų grąžinimas" "banką mokestis")
# Array with columns of origin xlsx for search and copy
arrColOrigin=("Payment purpose" "Date" "Turnover")
# Arrays with columns and values which are nessecary & useful for csv import in pp
arrColNew=(Typ Wert Datum)
arrValNew=(Zinsen Entnahme Einlage Steuern Zinsen Gebühren)
# Array with helper files and at least final output file
arrFile=("interest.csv" "withdrawal.csv" "funding.csv" "tax.csv" "delayed.csv" "fee.csv" "out.csv" "neofiance.csv")
#Remove first three rows of csv.
sed '1,3d' "$1" > "${arrFile[6]}"
for i in {0..5}
do
#For loop references variables inside of arrays i.e. interest -> Zinsen -> interest.csv
#should on same position inside of the different arrays.
#Scheme: Convert input xlsx to csv | find inside of selected column, selected string |
#cut selected columns |
#add new column (type) with selected value for each row > write to file
csvgrep -c "${arrColOrigin[0]}" -m "${arrFind[i]}" "${arrFile[6]}" |
csvcut -c "${arrColOrigin[1]}","${arrColOrigin[2]}" |
csvstack -n "${arrColNew[0]}" -g "${arrValNew[i]}" > "${arrFile[i]}"
done
# Merge separately helper files to one file
csvstack "${arrFile[0]}" "${arrFile[1]}" "${arrFile[2]}" "${arrFile[3]}" "${arrFile[4]}" "${arrFile[5]}" > "${arrFile[6]}"
# Adjust head row | format delimiter > write to final output file
csvsql --query "select [${arrColOrigin[1]}] as "${arrColNew[2]}", "${arrColNew[0]}", \
"${arrColOrigin[2]}" as "${arrColNew[1]}" \
from ${arrFile[6]::-4}" "${arrFile[6]}" |
csvformat -D ";" > "${arrFile[7]}"
#Remove helper files.
rm "${arrFile[0]}" "${arrFile[1]}" "${arrFile[2]}" "${arrFile[3]}" "${arrFile[4]}" "${arrFile[5]}" "${arrFile[6]}"
Beim CSV-Import muss für beide Dateien das Format der Spalte Datum auf “JJJJ-MM-TT” und der Spalte Wert auf “0,000.00” umgestellt werden. Ich hatte noch keine sinnvolle Idee, dass ohne großene Aufwand umzuschreiben. Und das Format auf locale de_DE umzuschreiben, gibt m.E. das csvkit-Tool nicht her.
Vielleicht hilft es den einen oder andern weiter.
1 Like