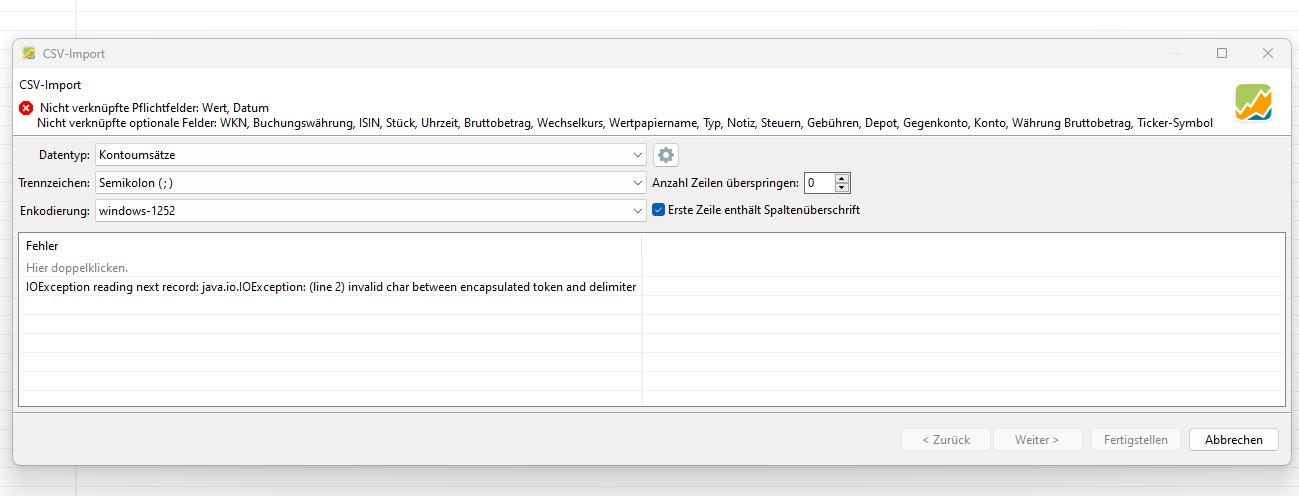
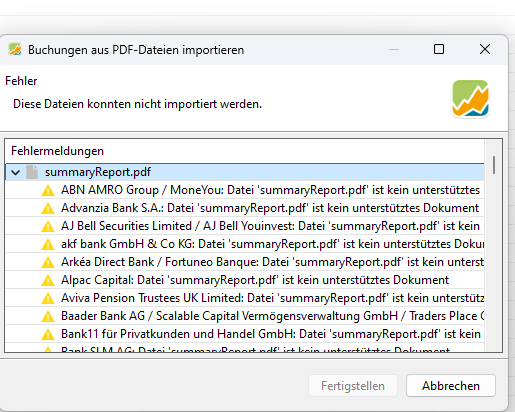
@Forenadmins
Sorry, für den Doppelpost. Ich habe zwar das Bearbeiter-Abzeichen, bin aber zu doof die Bearbeitungsfunktion aufzurufen.
Weitere Skripte nach den selben Schema:
Mintos:
#!/bin/bash
#This script convert xlsx of swaper account statement for csv import to portfolio performance.
#Just interests, fees, tax, withdrawals and fundings are converted to csv. But you can adjust this.
#This script use the python tool csvkit it must be installed.
#Usage: ./script.sh downloaded-statement.xlsx
# Array with strings to find inside of origin xlsx
arrFind=("Zins" "Abhebung" "Eingehende Zahlungen" "Verzugsgebühren" "Servicegebühr")
# Array with columns of origin xlsx for search and copy
arrColOrigin=("Einzelheiten" "Datum" "Umsatz")
# Arrays with columns and values which are nessecary & useful for csv import in pp
arrColNew=(Typ Wert Datum)
arrValNew=(Zinsen Entnahme Einlage Zinsen Gebühren)
# Array with helper files and at least final output file
arrFile=("interest.csv" "withdrawal.csv" "funding.csv" "delayed.csv" "fee.csv" "out.csv" "mintos.csv")
for i in {0..4}
do
#For loop references variables inside of arrays i.e. interest -> Zinsen -> interest.csv
#should on same position inside of the different arrays.
#Scheme: Convert input xlsx to csv | find inside of selected column, selected string |
#cut selected columns |
#add new column (type) with selected value for each row > write to file
csvgrep -c "${arrColOrigin[0]}" -m "${arrFind[i]}" "$1" |
csvcut -c "${arrColOrigin[1]}","${arrColOrigin[2]}" |
csvstack -n "${arrColNew[0]}" -g "${arrValNew[i]}" > "${arrFile[i]}"
done
# Merge separately helper files to one file
csvstack "${arrFile[0]}" "${arrFile[1]}" "${arrFile[2]}" "${arrFile[3]}" "${arrFile[4]}" > "${arrFile[5]}"
# Adjust head row | format delimiter > write to final output file
csvsql --query "select [${arrColOrigin[1]}] as "${arrColNew[2]}", "${arrColNew[0]}", \
"${arrColOrigin[2]}" as "${arrColNew[1]}" \
from ${arrFile[5]::-4}" "${arrFile[5]}" |
csvformat -D ";" > "${arrFile[6]}"
#Remove helper files.
rm "${arrFile[0]}" "${arrFile[1]}" "${arrFile[2]}" "${arrFile[3]}" "${arrFile[4]}" "${arrFile[5]}"
Viainvest:
#!/bin/bash
#This script convert xlsx of swaper account statement for csv import to portfolio performance.
#Just interests, withdrawals and fundings are converted to csv. But you can adjust this.
#This script use sed, the python tools xlsx2csv and csvkit it must be installed.
#Usage: ./script.sh downloaded-statement.xlsx
# Array with strings to find inside of origin xlsx
arrFind=("Zinsbetrag" "eingezahlten Mittel" "ausgezahlten Mittel")
# Array with columns of origin xlsx for search and copy
arrColOrigin=("Transaktionsart" "Transaktionsdatum" "Kredit (€)" "Debit (€)")
# Arrays with columns and values which are nessecary & useful for csv import in pp
arrColNew=(Typ Wert Datum)
arrValNew=(Zinsen Einlage Entnahme)
# Array with helper files and at least final output file
arrFile=("interest.csv" "funding.csv" "withdrawal.csv" "out.csv" "viainvest.csv")
for i in {0..1}
do
#For loop references variables inside of arrays i.e. interest -> Zinsen -> interest.csv
#should on same position inside of the different arrays.
#Scheme: Convert input xlsx to csv | find inside of selected column, selected string |
#cut selected columns |
#add new column (type) with selected value for each row > write to file
xlsx2csv "$1" | csvgrep -c "${arrColOrigin[0]}" -m "${arrFind[i]}" |
csvcut -c "${arrColOrigin[1]}","${arrColOrigin[2]}" |
csvstack -n "${arrColNew[0]}" -g "${arrValNew[i]}" > "${arrFile[i]}"
done
xlsx2csv "$1" | csvgrep -c "${arrColOrigin[0]}" -m "${arrFind[2]}" |
csvcut -c "${arrColOrigin[1]}","${arrColOrigin[3]}" |
csvstack -n "${arrColNew[0]}" -g "${arrValNew[2]}" > "${arrFile[3]}"
csvsql --query "select [${arrColNew[0]}], [${arrColOrigin[1]}], \
[${arrColOrigin[3]}] as [${arrColOrigin[2]}] \
from ${arrFile[3]::-4}" "${arrFile[3]}" | csvformat > "${arrFile[2]}"
# Merge separately helper files to one file
csvstack "${arrFile[0]}" "${arrFile[1]}" "out2.csv" > "${arrFile[3]}"
#csvstack "${arrFile[0]}" "${arrFile[1]}" > "${arrFile[3]}"
# Adjust head row | format delimiter > write to final output file
csvsql --query "select [${arrColOrigin[1]}] as [${arrColNew[2]}], [${arrColNew[0]}], \
[${arrColOrigin[2]}] as [${arrColNew[1]}] \
from ${arrFile[3]::-4}" "${arrFile[3]}" |
csvformat -D ";" > "${arrFile[4]}"
#Remove helper files.
rm "${arrFile[0]}" "${arrFile[1]}" "${arrFile[2]}" "${arrFile[3]}"
Twino:
#!/bin/bash
#This script convert xlsx of swaper account statement for csv import to portfolio performance.
#Just interests, withdrawals and fundings are converted to csv. But you can adjust this.
#This script use sed, the python tools xlsx2csv and csvkit it must be installed.
#Usage: ./script.sh downloaded-statement.xlsx
arrFind=(INTEREST FUNDING)
varColNrDescr=4
varColNrType=3
varColNrDate=1
varColNrAmount=6
varDiff="-" #Difference between withdrawal and funding is just negative and positive Amount
arrColOrigin=("Description" "Processing Date" "Amount, EUR")
# Arrays with columns and values which are nessecary & useful for csv import in pp
arrColNew=(Typ Wert Datum)
arrValNew=(Zinsen Entnahme Einlage)
# Array with helper files and at least final output file
arrFile=("interest.csv" "withdrawal.csv" "funding.csv" "out.csv" "twino.csv")
xlsx2csv "$1" > "${arrFile[0]}"
sed '1,2d' "${arrFile[0]}" > "${arrFile[3]}"
csvgrep -c $varColNrDescr -m "${arrFind[0]}" "${arrFile[3]}" | csvcut -c $varColNrDate,$varColNrAmount |
csvstack -n "${arrColNew[0]}" -g "${arrValNew[0]}" > "${arrFile[0]}"
csvgrep -c $varColNrType -m "${arrFind[1]}" "${arrFile[3]}" | csvgrep -c 6 -m "$varDiff" |
csvcut -c $varColNrDate,$varColNrAmount |
csvstack -n "${arrColNew[0]}" -g "${arrValNew[1]}" > "${arrFile[1]}"
csvgrep -c $varColNrType -m "${arrFind[1]}" "${arrFile[3]}" | csvgrep -i -c 6 -m "$varDiff" |
csvcut -c $varColNrDate,$varColNrAmount |
csvstack -n "${arrColNew[0]}" -g "${arrValNew[2]}" > "${arrFile[2]}"
csvstack "${arrFile[0]}" "${arrFile[1]}" "${arrFile[2]}" > "${arrFile[3]}"
csvsql --query "select [${arrColOrigin[1]}] as "${arrColNew[2]}", "${arrColNew[0]}", \
[${arrColOrigin[2]}] as "${arrColNew[1]}" \
from ${arrFile[3]::-4}" "${arrFile[3]}" |
csvformat -D ";" > "${arrFile[4]}"
rm "${arrFile[0]}" "${arrFile[1]}" "${arrFile[2]}" "${arrFile[3]}"

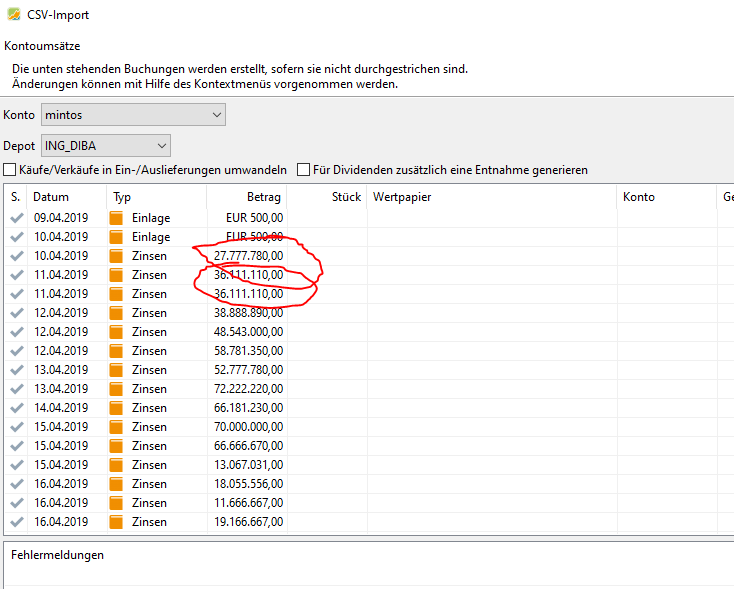
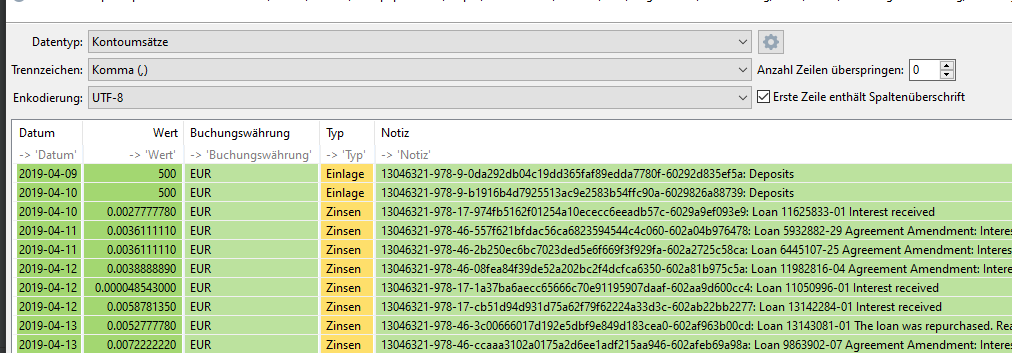



")