Shreibe mir bitte eine mail an info@abc234.de und ich maile dir dann meine PP-Datei zu.
Mag sein, es gibt aber noch eine Reihe weiterer Widgets, die den Datenbestand bei jedem GUI-Update neu durchgrasen. EarningsListWidget sei hier als Beispiel genannt (bei dem ich mir ein Caching der errechneten Werte schon auf meine innere TODO-Liste gesetzt habe, was ich angehe, sobald/sofern ich beim zugehörigen Github Issue mehr Feedback erhalten habe).
Daher dürfte
so pauschal nicht korrekt sein. Dass viel Redundanz passiert, habe ich gestern gesehen, als ich spaßeshalber mal meine PP-Datei mit laufendem Profiler geladen habe. Der Aufbau des Performance-Bereichs hat 1,4 Sekunden CPU-Zeit benötigt, eine Sekunde davon ging in PortfolioLog.log drauf, weil 51 mal die Konsistenzprüfung lief und er sich jeweils über die negativen Bestände meiner offenen Optionen mockierte.
Das kann man so ad hoc nicht beantworten.
Das kommt in mehrerlei Hinsicht nicht in Betracht. Zum einen würdest du viel mehr Berechnungen durchführen als normalerweise notwendig, weil “da draußen” vermutlich niemand alle Widgets gleichzeitig nutzt. Im blödesten Fall erzielst du damit bei der Mehrheit der Benutzer eine Verlangsamung der Applikation.
Ebenso würde so etwas den kompletten Umbau der Applikation erfordern und die Logik eines Widgets über die komplette Applikation verteilen. Ersteres wäre ein riesiger Aufwand, letzteres ein Alptraum bei der Codepflege. Meine ersten Ideen gingen aber in eine ähnliche Richtung, sind aber wegen des erwähnten Aufwands beim Umbau der kompletten Logik, wie Dinge berechnet werden, ebensowenig praktikabel: Die Widget “registieren” sich an einer zentralen Stelle als vorhanden. Soll neu berechnet werden, geht eine zentrale Schleife durch die Buchungen durch und legt sie den einzelnen Widgets jeweils vor die Füße, die dann für sich entscheiden können, ob damit etwas angefangen wird oder nicht. Damit würde man nur einmal durch den Datenbestand gehen und nicht - wie oben anhand der erwähnten Logmeldungen zu vermuten - 51 mal.
Die Realisierung wäre aber auch hier wie bei deinem Vorschlag ein kompletter Umbau, wie die Applikation an der Stelle funktioniert. So was wird daher vermutlich eher nicht passieren ![]()
Vielleicht hilft Parallelisierung etwas, d.h. man nutzt mehrere Prozessoren. Hab mir aber die Sourcen in der Tiefe noch nicht verinnerlicht, daher kann es sein, dass das schon längst passiert. Mal schauen… Ist auf jeden Fall etwas, dass Zeit braucht - die man erst mal haben muss ![]()
Kleiner Zwischenstand mit einem Kandidaten bei der Vermögensübersicht ![]()

Angezeigt werden die Anzahl erzeugter Objekte und deren Größe.
Aus irgendeinem Grund beschränkt sich die VM Hier[TM] auf 1 GB Speicher (obwohl ich bis 32 GB erlaubt habe), so dass viel Zeit im Garbage Collector verging.
Bei der Performanceübersicht ein ähnliches Bild:

Das mal nur als kleines Zwischenergebnis. Wer die fraglichen Klassen und Methoden besser kennt als ich, hat ja vielleicht schon mal eine Idee, was sich hier eventuell verbessern lässt.
Ist das die Datei mit den monströs vielen Buchungen? Die werden im clientSecurityFilter gefiltert, also letztlich kopiert (ggf. in modifizierter Form).
könnte PP eine Art “Auto Bereinigen” Funktion integrieren, die genau das macht was du beschrieben hast. Also alle inaktiven Wertpapiereinträge und historischen Kurse zu bereinigen?
Bloß nicht. Das sollte man nämlich nicht tun, wenn man an richtigen Auswertungen interessiert ist.
Das stimmt, ich habe mir zu jedem Wertpapier angeschaut ab wann ich die historischen Kurse benötige. Manchmal waren es 1 Jahr bei anderen 15 Jahre.
Was jetzt? Gefiltert oder kopiert? ![]() Ich muss mir das noch im Detail anschauen, aber eine erste Hypothese ist die Verwendung von
Ich muss mir das noch im Detail anschauen, aber eine erste Hypothese ist die Verwendung von Money für die Berechnung. Das sind immutable Objekte - so ähnlich wie BigInteger - so dass man massiv viele davon produziert, wenn man etwas aufsummiert, was ja beim TTWROR der Fall ist.
Wenn dann noch - zweite Hypothese - der TTWROR jeweils pro Wertpapiert berechnet werden sollte und dabei dann aufs Neue durch die Gesamtzahl der Buchungen durchgegangen wird, durchgrast man den Datenbestand unnötig oft und erzeugt dabei eigentlich unnötig viele Objekte.
Eigentich sind die aktuellen Garbage Collectoren inwischen sehr gut, bei diesem Szenario performant die verbrauchten Objekte abzuräumen, aber irgendwann hilft das halt nicht mehr und man merkt einen Performanceverlust. Und um ein Argument von weiter oben gleich anzugehen: Das Problem hat nichts mit Java zu tun, in C++ hätte man mit den gleichen Problemen zu kämpfen. Nur in Assembler nicht, weil man dort mit der Implementierung einer Applikation wie PP noch bis heute beschäftigt wäre. ![]()
Die historischen Kurse spielen bei den vom Profiler oben gezeigten “Bottle Necks” keine Rolle und wenn du inaktive Wertpapiere löscht, die du aber mal gehalten und mit Gewinn/Verlust veräussert hast, verfälscht du deine Performanceberechnung.
Nie gehandelte, inaktive Papiere und die historischen Kurse von inaktiven Papieren allgemein könnte man mit so einem Mechanismus löschen, das hat aber nur einen Einfluß auf die Größe der PP-Datei. Auf die Performance im laufenden Betrieb hat das aber nicht wirklich eine relevante Wirkung.
Ist das so unverständlich? Es wird eine Kopie angelegt, die nur einen Teil der ursprünglichen Einträge enthält (nämlich nicht die ausgefilterten) und bei der die Einträge teilweise modifiziert sind (nämlich z.B. eine Entnahme, wenn es ursprünglich eine Umbuchung auf ein Konto war, das jetzt nicht im Filter enthalten ist). Wobei „modifizierter Eintrag“ natürlich auch bedeutet, dass eine Kopie des Eintrags modifiziert wird, denn das Original bleibt selbstverständlich unverändert erhalten.
Nicht grundsätzlich, aber offensichtlich wurde hier eine wertpapierbezogene Datenreihe verwendet.
Wenn ich den Ablauf anhand des Memorysnapshots korrekt interpretiert habe, wird eine Map nach Securities gruppiert aufgebaut, deren Wert dann die berechneten Werte enthält. Es wird aber wohl pro Wertpapier jedes mal aufs Neue erst mal durch den gesamten Bestand an Transaktionen gegangen, um die für das Wertpapier relevanten herauszusuchen. Das ergibt Anzahl Wertpapiere x Anzahl Transaktionen Durchläufe. Ist zwar nicht exponentiell, aber das ganze wird dann doch recht schnell zeitaufwändig, wenn man mal mehr Wertpapiere oder einen längeren Zeitraum zu verarbeiten hat. Die mir vorliegende Datei ist da ein bisschen extrem, was Anzahl Wertpapiere (mehrere hundert) und Transaktionen (mehrere tausend) angeht, “da draußen” wird das aber mit zunehmender erfasster Zeit früher oder später jeden treffen.
Eine Lösung wäre eine Umstellung der Berechnung, dass man eben einmal durch den Transaktionsbestand geht und dann beim jeweils passenden Wertpapierteil die aktuelle Berechnung durchführt. Das ist aber eine größere Umstellung und nicht mal eben machbar. Am Ende wäre der Durchlauf aber Hier[TM] dann um einen dreistelligen Faktor schneller, ohne dass sich etwas am Speicherverbrauch ändern würde. Man könnte als Zwischenlösung die Berechnung parallelisieren, d.h. mehrere Wertpapiere gleichzeitig bearbeiten (passenden Stream suchen und parallelStream statt stream verwenden). Braucht dann aber mehr Speicher und der Performancegewinn wäre nur ein einstelliger Faktor.
Das ganze bezieht sich auf die Vermögensübersicht. Das Dashboard ist noch mal ein anderes Thema, für das ich einen eigenen Memorysnapshot (und CPU-Snapshot) erstellt habe, mir aber noch nicht die Zeit genommen habe, das anzuschauen. Da dürfte es aber auf etwas Ähnliches hinauslaufen, denke ich.
Vielen Dank für die Zeit und Mühe die du hier aufwendest. Ich weiß dass mein Depot auf jeden Fall nicht dem eines durchschnittlichen Anlegers gleicht, aber ich stimme dir zu: Dieses Problem wird jeden ambitionierten Anleger nach einigen Jahren betreffen, sofern er nicht nur wenige Aktien hält.
Das klingt plausibel und ich würde mich über jedes % freuen.
Da bin ich mal gespannt, das Dashboard ist bei mir ja das Hauptproblem.
Ein Problem der aktuellen Implementierung ist sicherlich, dass bei der Berechnung des TTWROR für jedes Datum alle Buchungen noch mal angeschaut werden.
Dazu habe ich mal einen Pull Request erstellt. Damit werden die Buchungen nur noch inkrementell dem Bestand hinzugebucht. Wenn Ihr den Pull request mal ausprobieren könntet, wäre ich dankbar. (@Topcgi - hast Du eine Entwicklungssetup? Schick mir eine Email wenn ich Dir einen Test Build bauen soll).
Es ist immer gefährlich micro benchmarking zu machen. Bei kleinen Portfolios (1 Jahr, 1500 Buchungen) macht es keinen Unterschied, bei großen Portfolios (10 Jahre, 5800 Buchungen) ist es deutlich bemerkbar.
| Spalte 1 | Spalte 2 |
|---|---|
| Vorher (ms) | Nachher (ms) |
| Test Case #1 | |
| 2 | 1 |
| 2 | 0 |
| 1 | 2 |
| 2 | 1 |
| 2 | 1 |
| 6 | 2 |
| 16 | 3 |
| 10 | 1 |
| 6 | 1 |
| Test Case #2 | |
| 58 | 51 |
| 185 | 77 |
| 130 | 23 |
| 65 | 12 |
| 40 | 9 |
| 818 | 92 |
Ich bin, was GitHub und git angeht, weiterhin erst am Anfang. Wie bekomme ich denn den Pull Request “rüber” zu meinem Fork? Beim Durchklicken der Webseiten ist mir da nichts offensichtliches ins Gesicht gesprungen.
@Topcgi hat mir ja für die Profilergeschichte seine (etwas anonymisierte) PP-Datei zur Verfügung gestellt. Eventuell kann er dir die auch direkt geben, dann hast du passendes “Spielmaterial” ![]()
Du hast doch bestimmt das PP repository als “upstream” in Deinem Git repository. Dann solltest Du da auch den branch “feature_performance_ttwror” sehen.
Ansonsten sollte auch laut Stack Overflow auch folgende Kommandos funktionieren:
git fetch upstream pull/$ID/head:$BRANCHNAME
git checkout $BRANCHNAME
Ich arbeite komplett über Eclipse, d.h. ich habe nicht mal git als Executable präsent und innerhalb Eclipse nur den Fork als Remote Repository konfiguriert.
Aber FWIW gibt es innerhalb von Eclipse einen Weg:
Kontextmenü aufs Projekt öffnen,
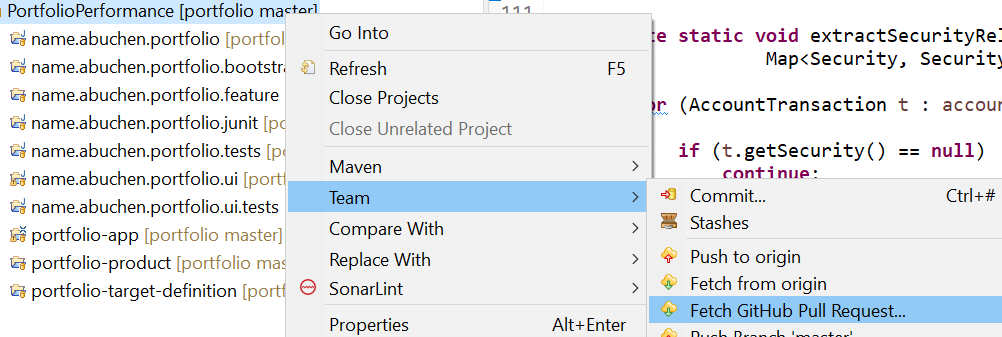
Im Dialog, das Upstreamrepository (oder welches auch immer) angeben, ebenso wie den Pullrequest:
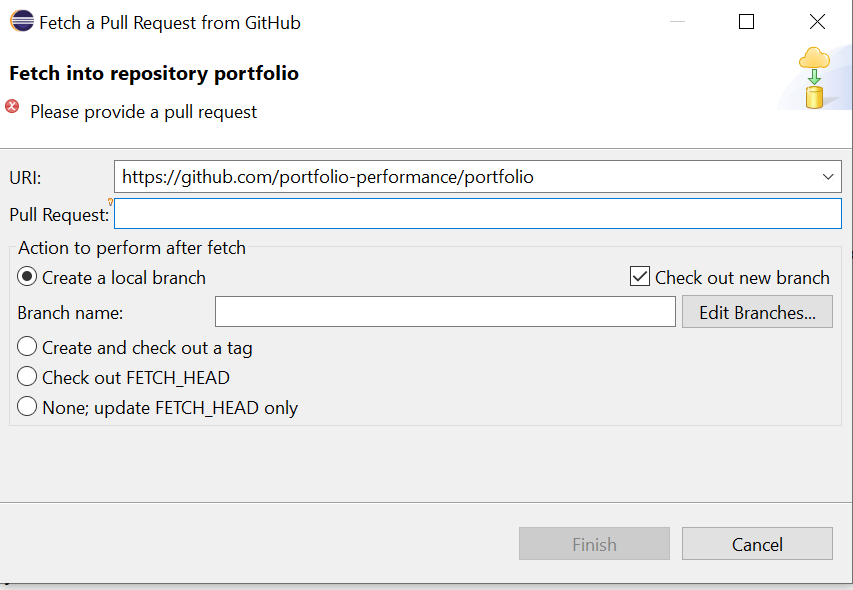
Für Letzteres kann man die URL - hier https://github.com/portfolio-performance/portfolio/pull/4093 - verwenden, Eclipse baut das dann automatisch passend um:
![]()
Wenn man den Rest der Einstellung belässt wie vorgeschlagen und auf OK klickt, zieht er sich den Pullrequest und erzeugt daraus einen neuen lokalen Branch.
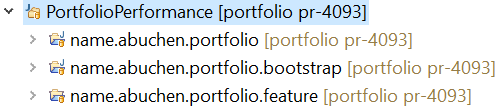
Mit diesem erhalte ich ungefähr eine Halbierung der Zeit bis zur Darstellung der Vermögensübersicht. Ich habe das jetzt aber nur hemdsärmlig mit einer Stoppuhr gemessen und nicht mittels Profiler bis ins Detail analysiert.
Ist jetzt nicht der Brüller, aber auf jeden Fall ein gutes Ergebnis für die relativ überschaubare Änderung. Um das in Zahlen auszudrücken: 5 Sekunden gegenüber 10 Sekunden davor.
@AndreasB Ich befürchte ein Entwicklungssetup wäre bei mir “Fehl am Platz”. Wenn ich mir hier die Fachgespräche so durchlese, dann verstehe ich viel zu wenig von Java. Ich beherrsche PHP / Perl / CGI etc. da könnte weiterhelfen.
@AndreasB Ich habe dir wie von @kimmerin vorgeschlagen, meine PP-Datei per Email geschickt. Darin findest du ein langfristiges Buy&Hold Portfolio mit der Dividendenstrategie die mittels 230 Aktien/ETFs über Sparpläne etc. dargestellt wird. Alle Buchungen sind “echte” Buchungen.
Danke @Topcgi für die Datei (und das Vertrauen).
Ich schreibe einfach mal auf, was mir so auffällt:
Erstens fallen beim Öffnen zwei Effekte übereinander - es ist eine aufwändig Ansicht mit 6 Performance Spalten und weil die parallel Kurse aktualisiert werden, werden die Berechnungen ständig invalidiert und neu ausgeführt. Wenn ich die Ansicht öffne ohne die Kurse zu aktualisieren (allerdings mit dem Patch), ist die Tabelle nach 1 oder 2 Sekunden da.
Aktuell wird nach 20 Kursaktualisierungen das UI neu berechnet. Es ist total schwer den richtigen “trade off” hin zu bekommen. Der User will ja auch die neue Werte sehen. Allerdings wenn die Berechnungen gerade teuer sind, sollte es seltener stattfinden.
@Topcgi Du könntest überlegen ob Du eine reduzierte erste Tabelle zur ersten Ansicht nach dem Öffnen konfigurierst.
- Es werden teilweise noch Berechnungen durchgeführt, die nicht notwendig da gar nicht angezeigt werden (z.B. Volatilität)
- Die Berechnung finden ich UI Thread statt - es wäre geschickter die im Background laufen zu lassen - dann reagiert zumindest noch das UI (und man könnte anstehende aber noch nicht berechnete Rechnungen wegwerfen wenn die Berechnungen invalidiert werden)
- Filter könnte man cachen (insbesondere wenn Buchungen nach Wertpapier gefiltert werden)
- Analog zur “SnapshotIterator” könnte man auch einen “SecurityPriceIterator” entwickeln, der ggf. schneller als die binary search ist (weil er weiß wo der nächste Kurse im Array sein könnte).
Ich finde es total schwer im Profiling zu sehen wo man am besten ansetzt. Ich meinte eine einfache Möglichkeit zu sehen - aber ohne Profiler war der Code in 0ms durch.
Ich bin offen für weitere Erkenntnisse aus dem Profiling
Wir reden übers Dashboard oder noch über die Vermögensübersicht? BTW, ganz unabhängig davon - wenn auch nicht ganz: Ein offline-Modus wäre super, der den Applikationsneustart übersteht. Dann muss man nicht bei jedem neuen Versuch den Abruf von 220 Wertpapieren abwarten und ich habe es bei meiner eigenen PP-Datei schon man geschafft, bei der Dividendenwidgetentwicklung in das stündliche Maximum an Anfragen bei Ariva zu rasseln.
Beim Dashboard hätte ich noch als Vorschlag, dass man bei der Liste der Transaktionen sicherstellt, dass sie absteigend nach Transaktionsdatum sortiert ist. Der hauptsächliche Use Case ist ja das Anzeigen von Zeiträumen von jetzt bis zu einem - meisst nicht zu weit - in der Vergangenheit liegenden Zeitpunkt. Sind die Daten wie genannt sortiert, kann das Zusammenstellen der Datenreihe sofort beendet werden, sobald man dem ersten Datum begegnet, das vor dem eingestellten Startdatum liegt.
Die Einstellung gibt es längst. Ich habe bei mir auch ewig schon aktiv und rufe Kurse nur manuell ab.
Nur dass es da noch die Werte „… seit der ersten Buchung“ gibt.
Selbst jetzt, wo ich weiß, dass es da was geben muss, finde ich keine Einstellung. Vielleicht kannst du das etwas ausführlicher beschreiben. Als Nutzer würde ich so eine Option unter dem Menüpunkt “Online” erwarten, wo man den Modus toggeln könnte.
Klar gibt es worst cases, aber ich behaupte mal, dass die hauptsächliche Nutzung des Dashboards darin besteht, dass man sich aktuelle Änderungen anzeigen lässt, d.h. in der Mehrzeit der Fälle, der aktuelle Tag, oder das aktuelle Jahr (YTD) als Zeitraum verwendet wird.